Back-Propagation is very simple. Who made it Complicated ?
Learning Outcome: You will be able to build your own Neural Network on a Paper.

Almost 6 months back when I first wanted to try my hands on Neural network, I scratched my head for a long time on how Back-Propagation works. When I talk to peers around my circle, I see a lot of people facing this problem. Most people consider it as a black-box and use libraries like Keras, TensorFlow and PyTorch which provide automatic differentiation. Though it is not necessary to write your own code on how to compute gradients and backprop errors, having knowledge on it helps you in understanding a few concepts like Vanishing Gradients, Saturation of Neurons and reasons for random initialization of weights
More about why is it important to Understand?
Andrej Karapathy wrote a blog-post on it and I found it useful.
Approach
- Build a small neural network as defined in the architecture below.
- Initialize the weights and bias randomly.
- Fix the input and output.
- Forward pass the inputs. calculate the cost.
- compute the gradients and errors.
- Backprop and adjust the weights and bias accordingly
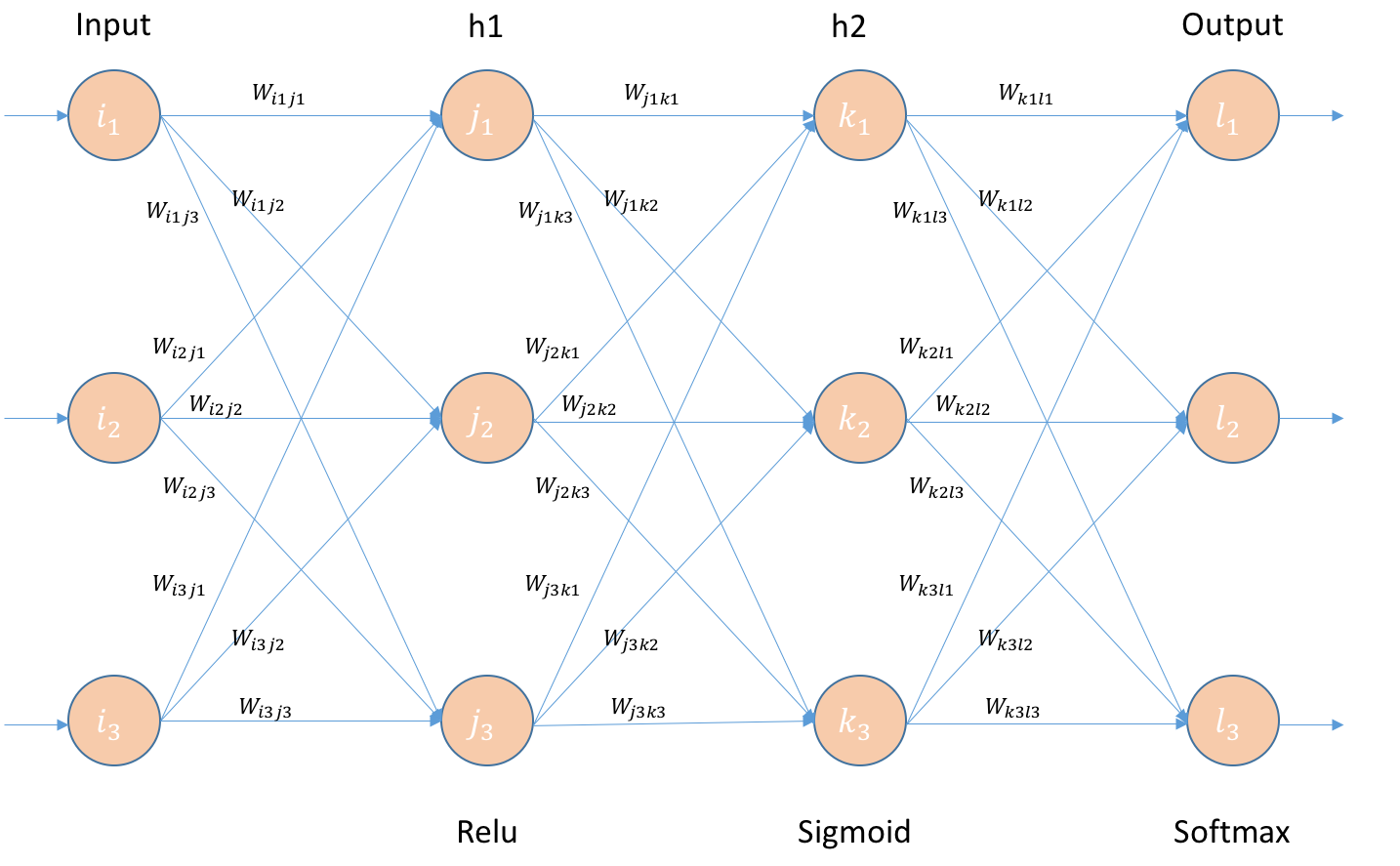
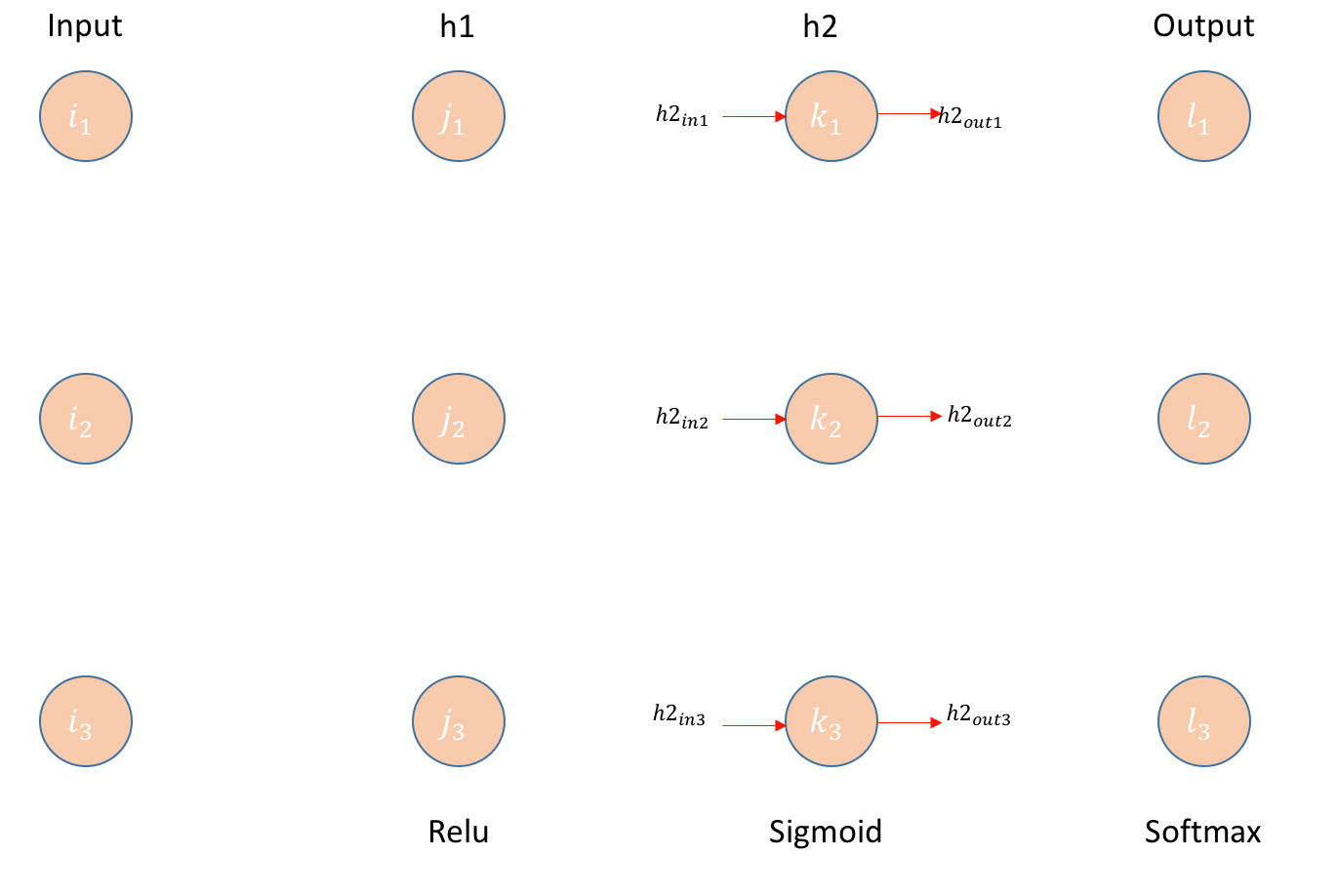
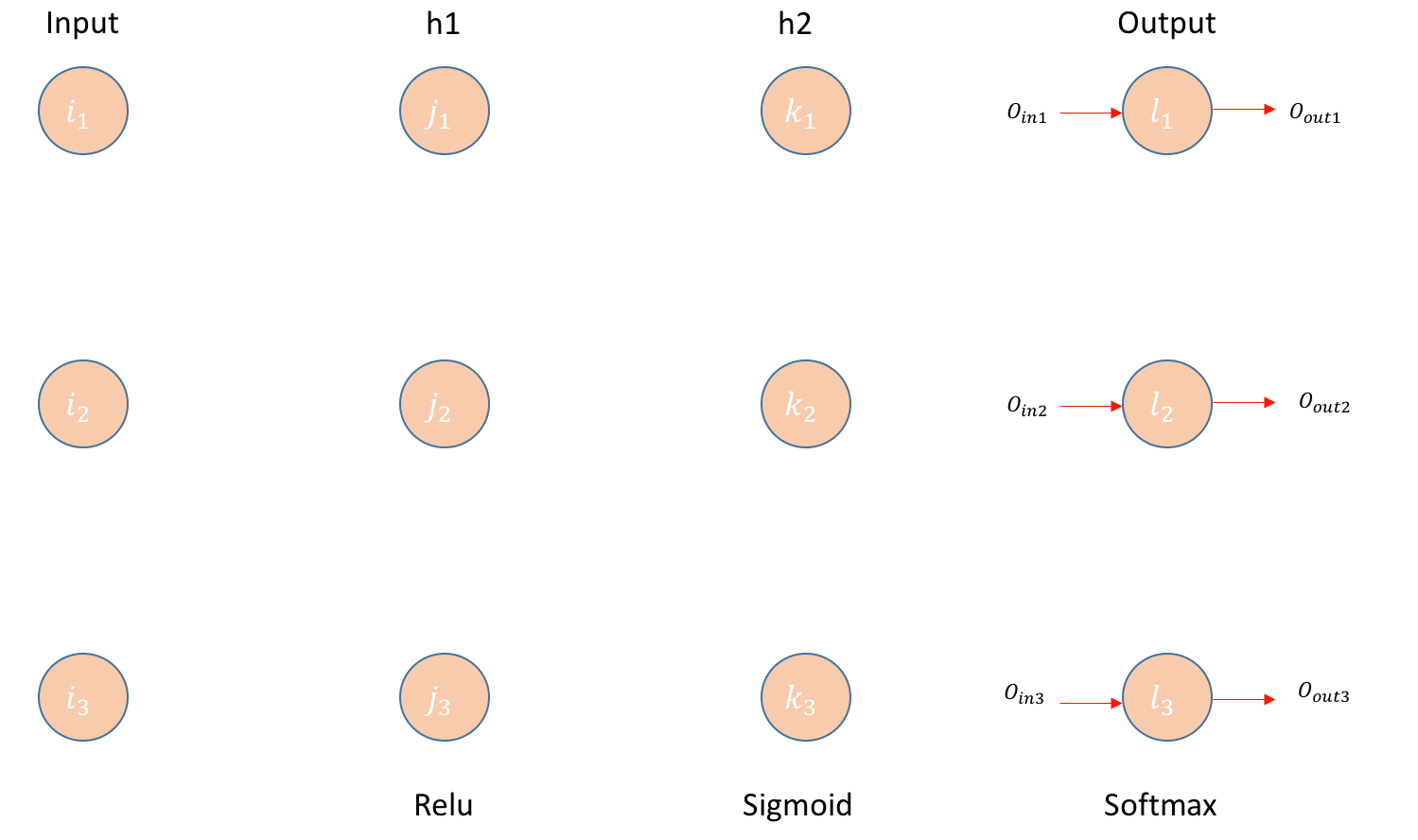
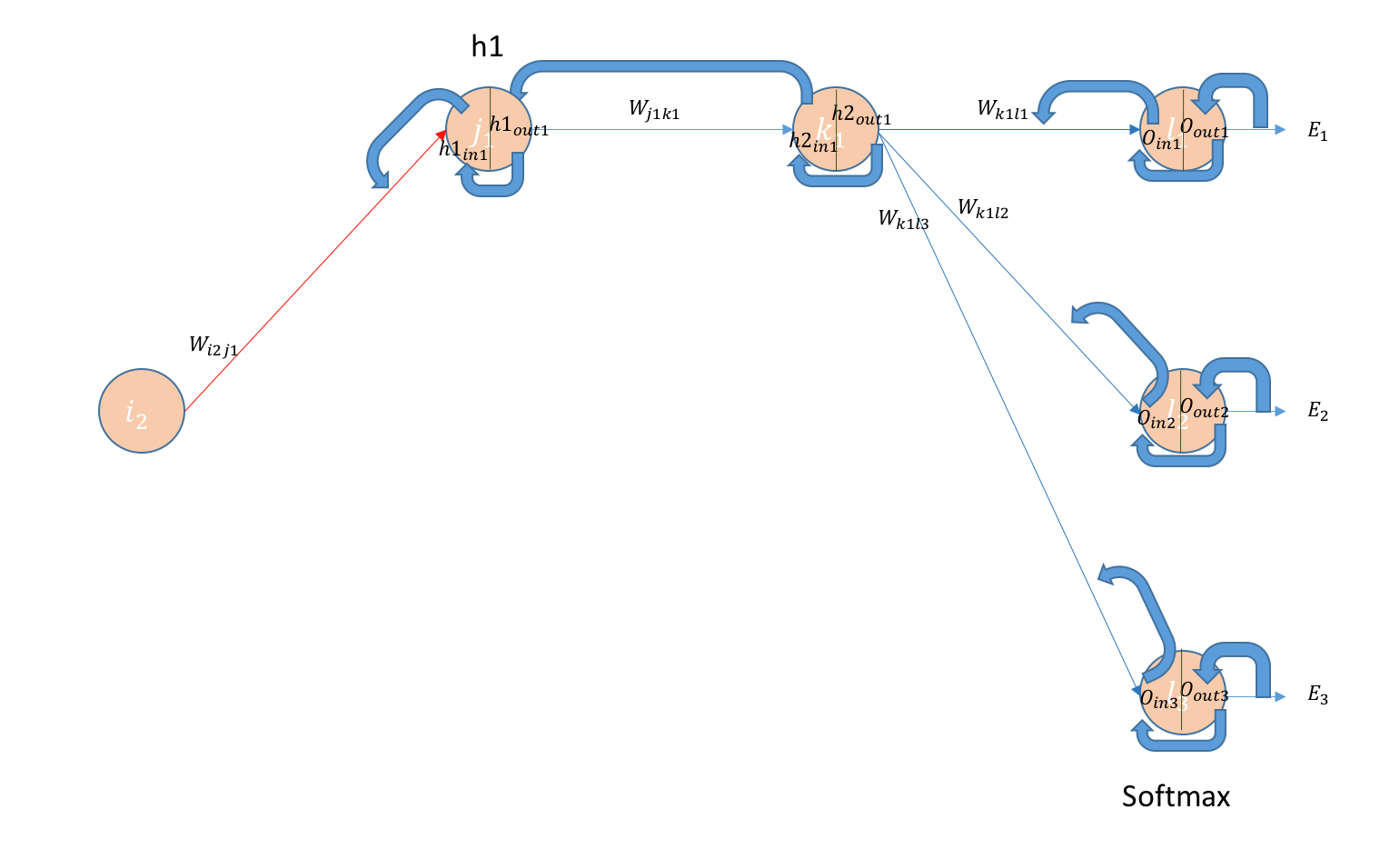
Architecture:
- Build a Feed Forward neural network with 2 hidden layers. All the layers will have 3 Neurons each.
- 1st and 2nd hidden layer will have Relu and sigmoid respectively as activation functions. Final layer will have Softmax.
- Error is calculated using cross-entropy.
Initializing the network
I have taken inputs, weights and bias randomly

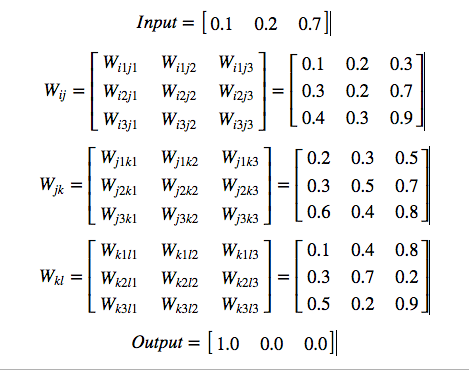

Layer-1

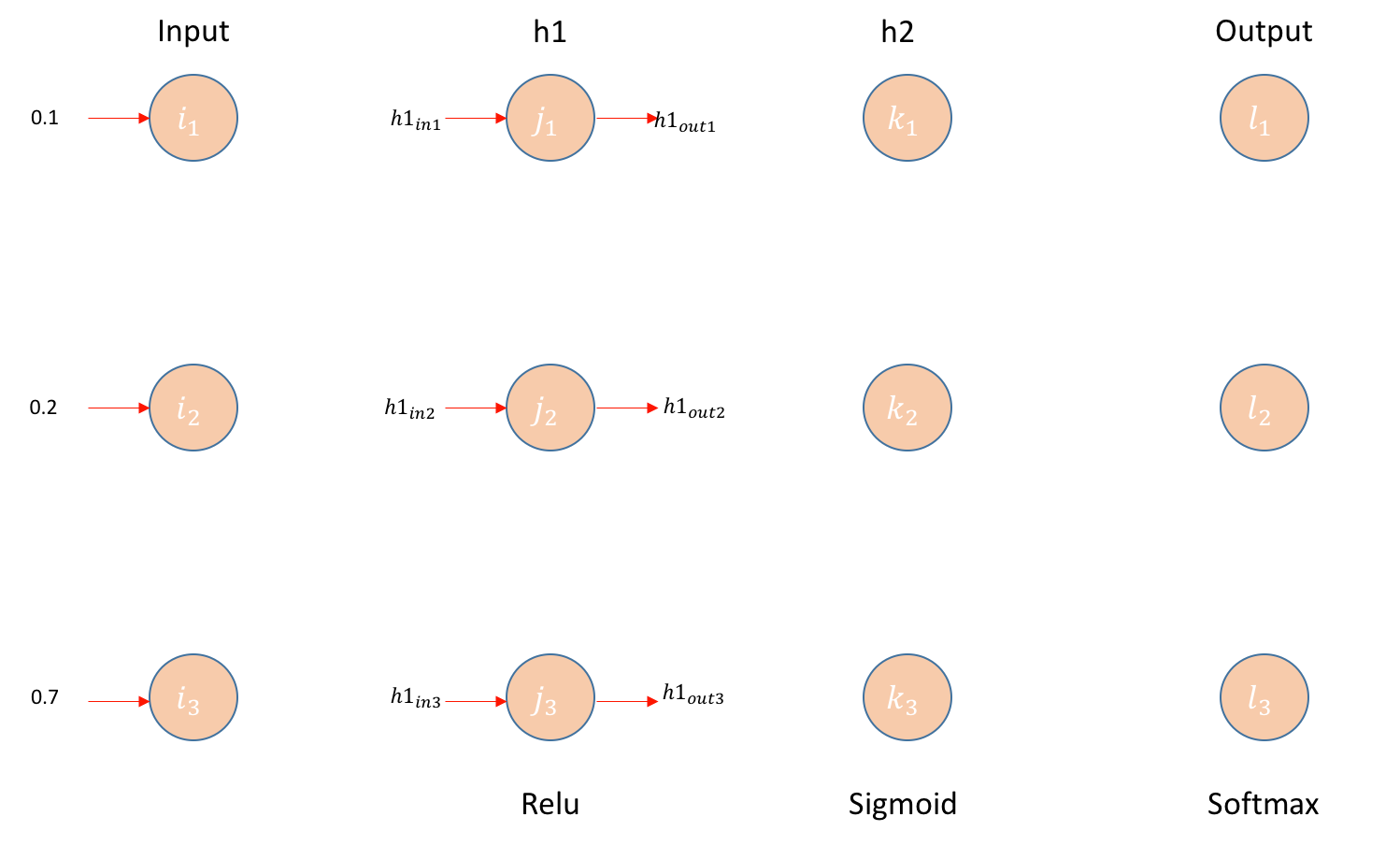
Matrix Operation:

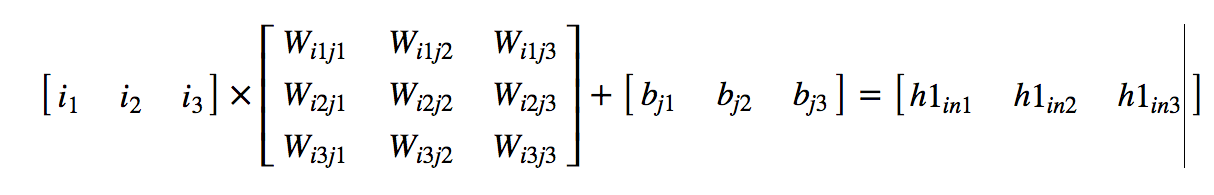
Relu operation:

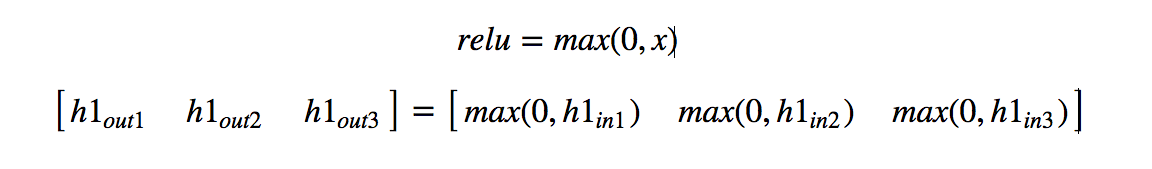

Example:

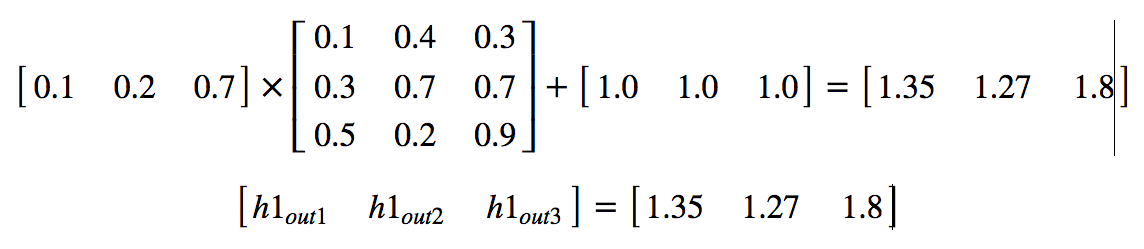
Layer-2

Matrix operation:

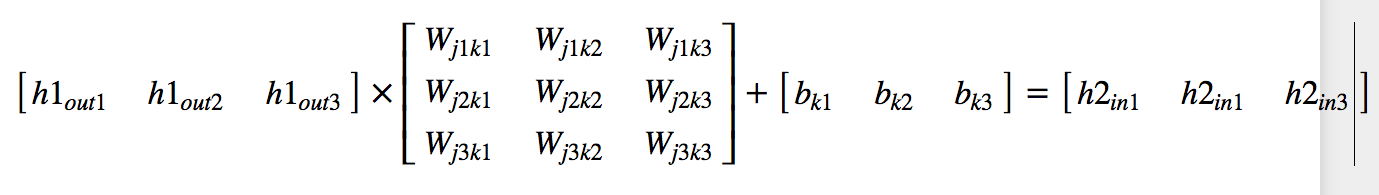
Sigmoid operation:

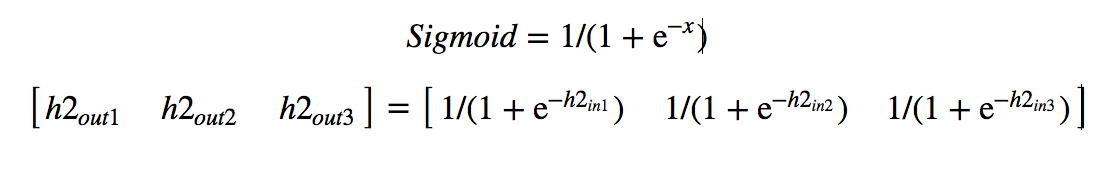
Example:

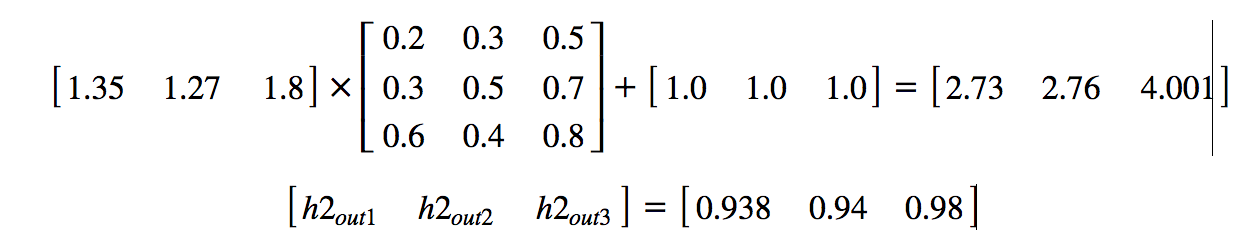

Layer-3

Matrix operation:

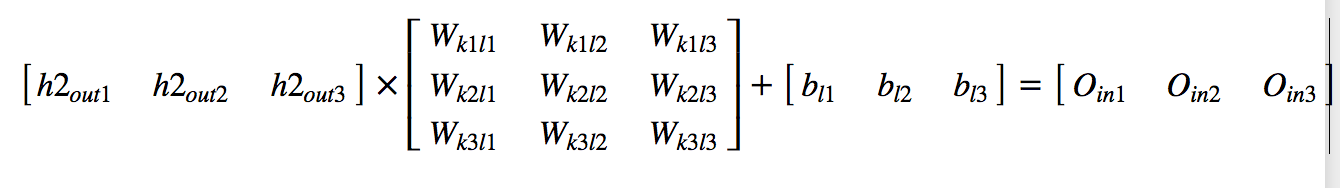
Softmax operation:

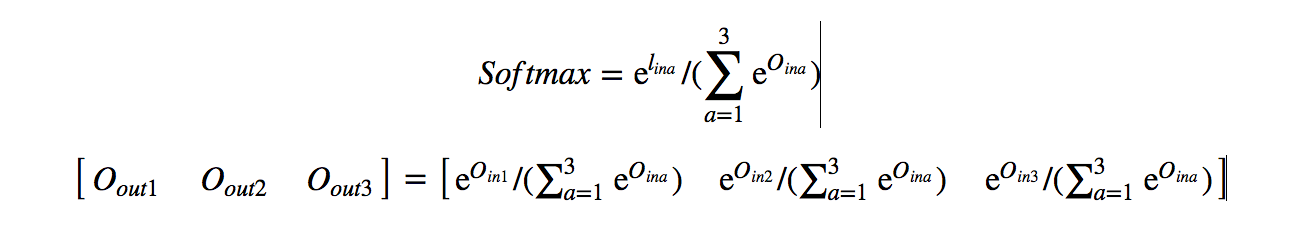
Example:

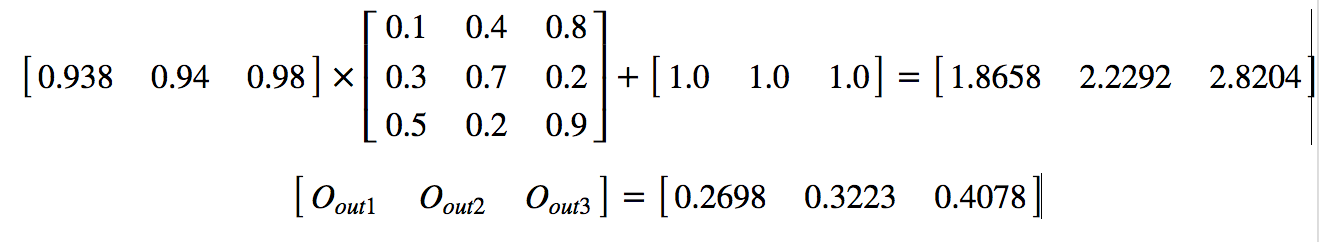

Edit1: As Jmuth pointed out in the comments, the output from softmax would be [0.19858, 0.28559, 0.51583] instead of [0.26980, 0.32235, 0.40784]. I have done a/sum(a) while the correct answer would be exp(a)/sum(exp(a)) . Please adjust your calculations from here on using these values. Thank you.
Analysis:
- The Actual Output should be [1.0, 0.0, 0.0] but we got [0.2698, 0.3223, 0.4078].
- To calculate error lets use cross-entropy
Error:
Cross-Entropy:

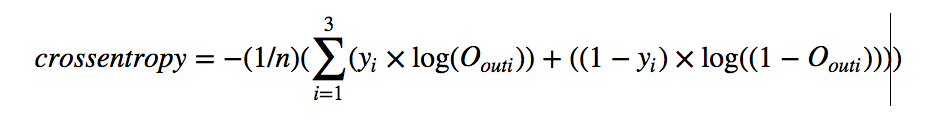
Example:

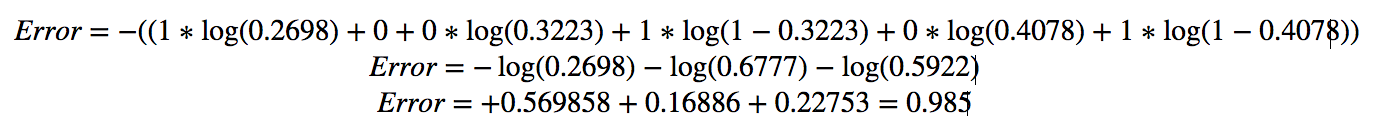

We are done with forward pass. Now let us see backward pass
Important Derivatives:
Sigmoid:

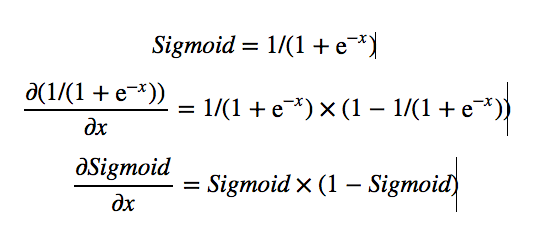
Relu:

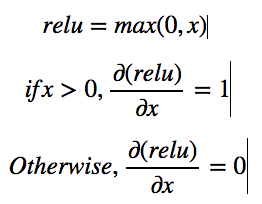
Softmax:

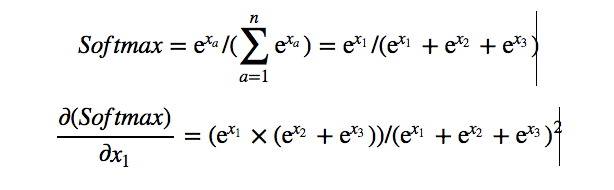
BackPropagating the error — (Hidden Layer2 — Output Layer) Weights

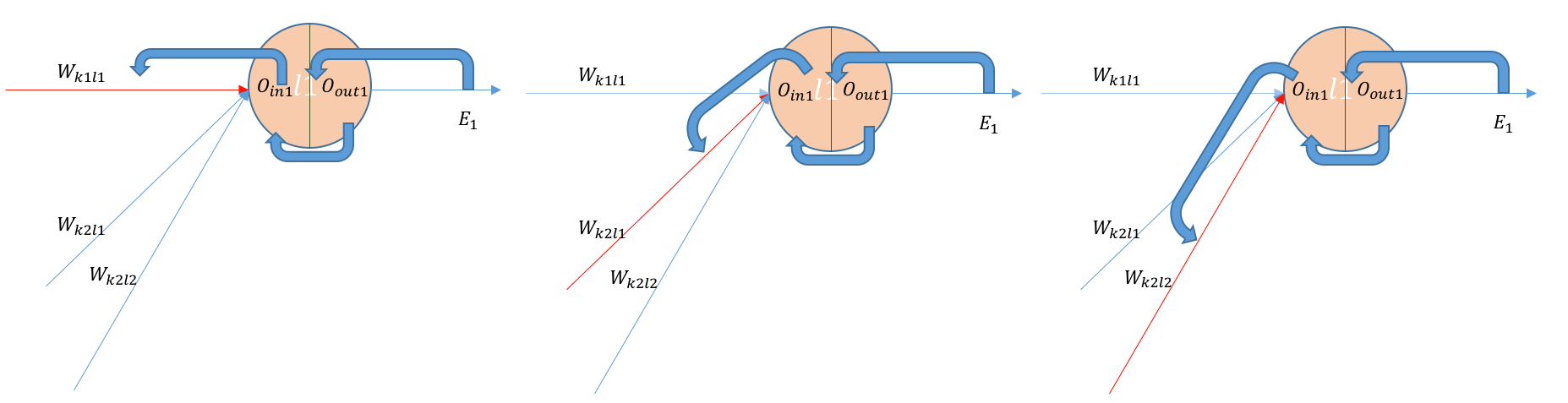
Let us calculate a few derivatives upfront so these become handy and we can
reuse them whenever necessary. Here are we are using only one example (batch_size=1), if there are
more examples, We just need to average everything.

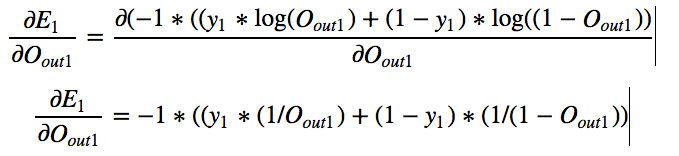
By symmetry we can calculate other derivatives also

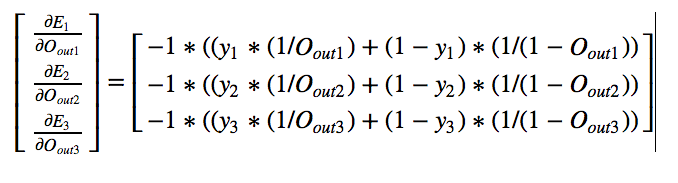
In our example,

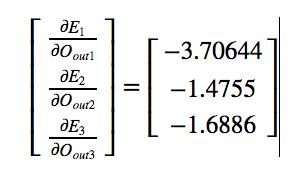
Next let us calculate the derivative of each output with respect to their
input.

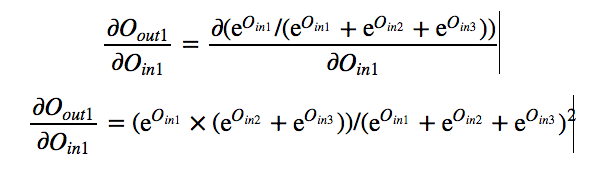
By symmetry we can calculate other derivatives also

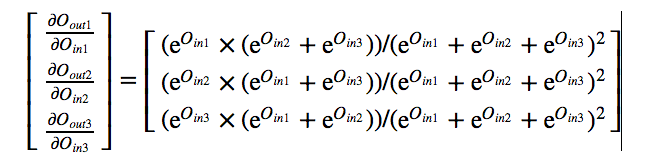
In our example,

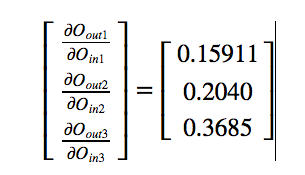
For each input to neuron let us calculate the derivative with respect to
each weight. Now let us look at the final derivative

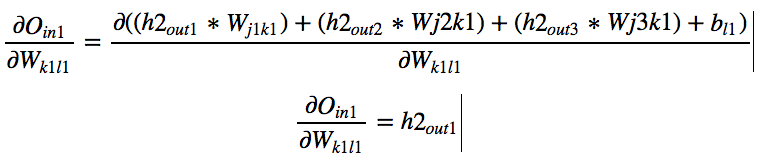
By symmetry we can calculate other derivatives also

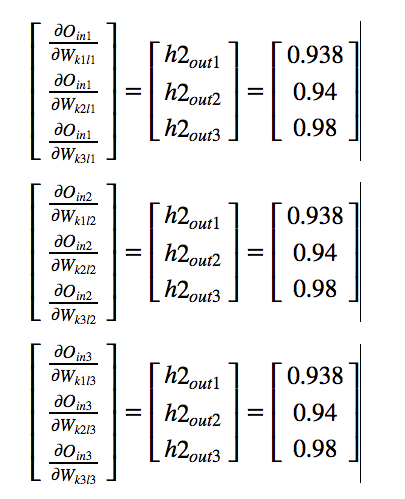
Finally Let us calculate the change in

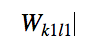
Which will be simply

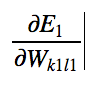
Using Chain Rule:

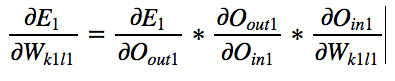
By symmetry:

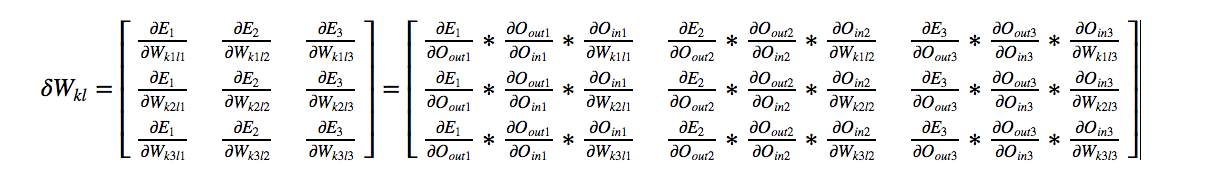
All of the above values are calculated before. We just need to substitute the results.


Considering a learning rate of 0.01 we get our final weight matrix as

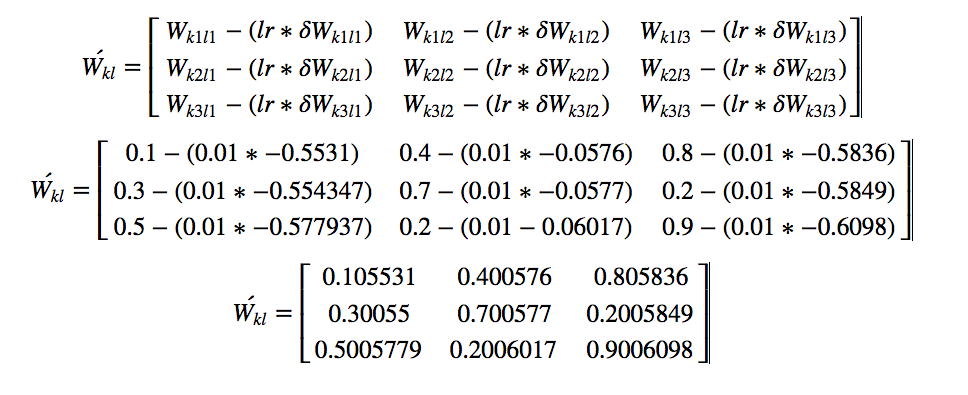

So, We have calculated new weight matrix for W_{kl}. Now let us move to the next layer:
BackPropagating the error — (Hidden Layer1 — Hidden Layer 2) Weights

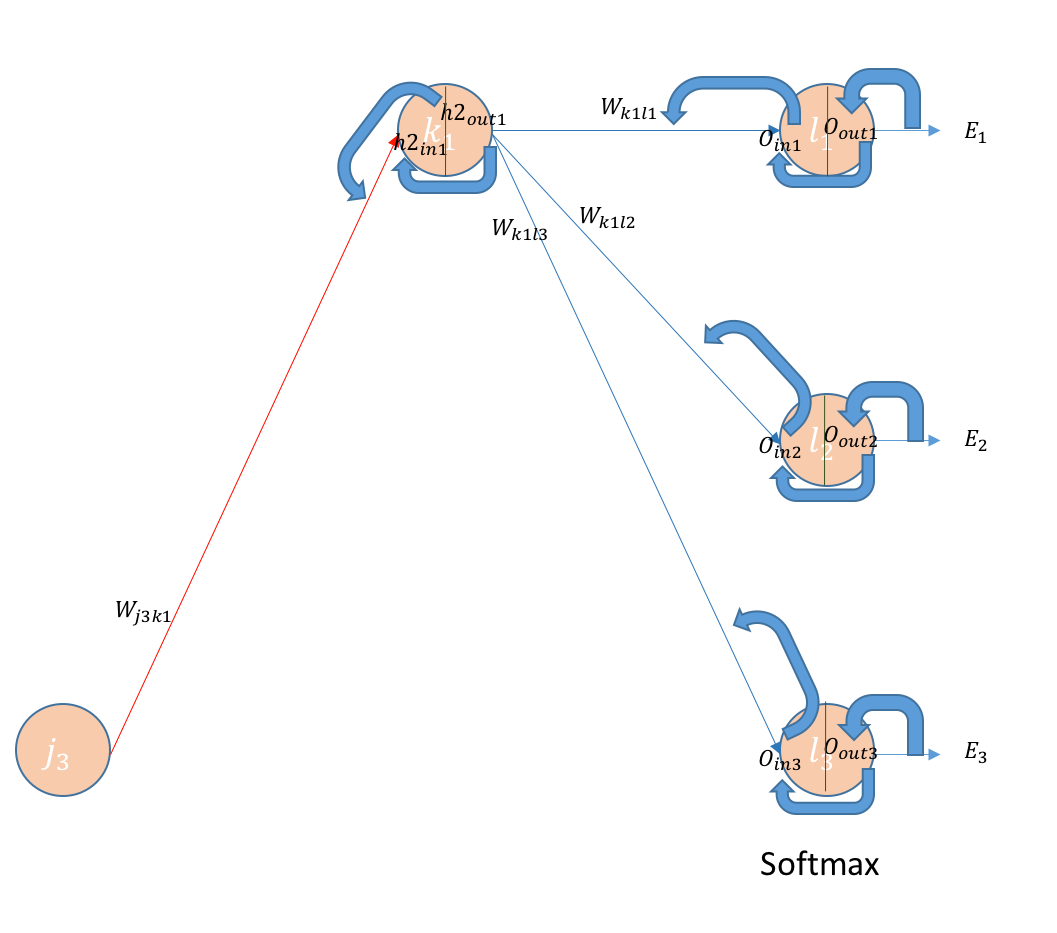
Let us calculate a few handy derivatives before we actually calculate the
error derivatives wrt weights in this layer.


In our example:

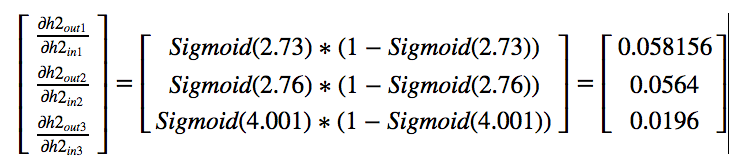
For each input to neuron let us calculate the derivative with respect to
each weight. Now let us look at the final derivative

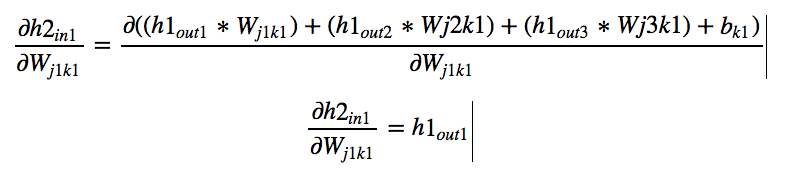
By symmetry we can calculate:


Now we will calculate the derivative of

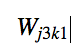
which will be simply.

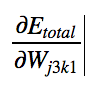
Using chain rule,

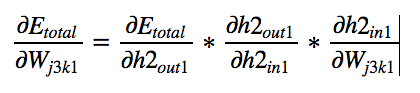
By symmetry we get the final matrix as,

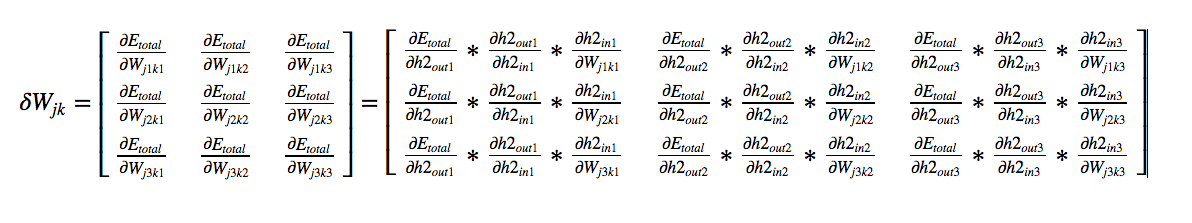
We have already calculated the 2nd and 3rd term in each matrix. We need to
check on the 1st term. If we see the matrix, the first term is common in all the columns. So there are
only three values. Let us look into one value

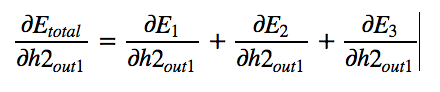
Lets see what each individual term boils down too.

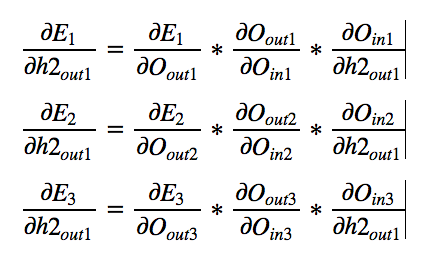
by symmetry we get the final matrix as,

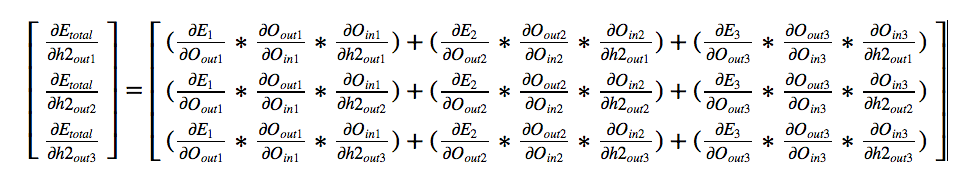
Again the first two values are already calculated by us when dealing with
derivatives of W_{kl}. We just need to calculate the third one, Which is the derivative of input to
each output layer wrt output of hidden layer-2. It is nothing but the corresponding weight which
connects both the layers.

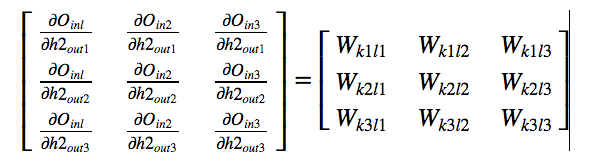

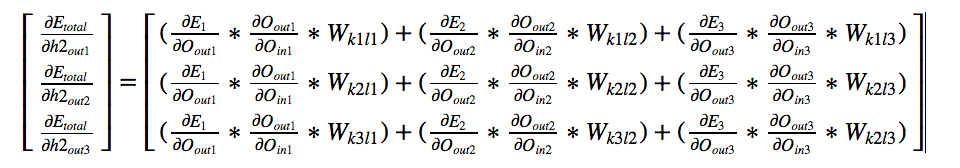
All Values are calculated before we just need to impute the corresponding
values for our example.

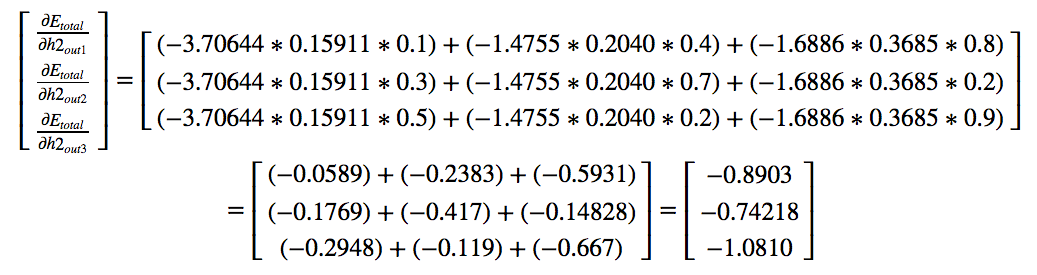
Let us look at the final matrix

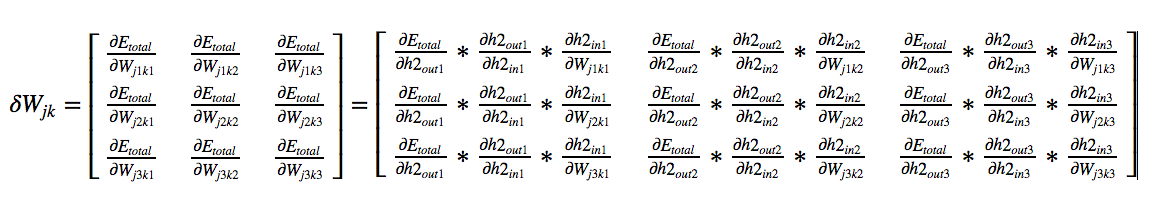
In our example,


Consider a learning rate (lr) of 0.01 We get our final Weight matrix as


So, We have calculated new weight matrix for W_{jk}. Now let us move to the next layer:
BackPropagating the error — (Input Layer — Hidden Layer 1) Weights.
Edit:1 the following calculations from here are wrong. I took only wj1k1 and ignored wj1k2 and wj1k3. This was pointed by an user in comments. I would like someone to edit the jupyter notebook attached at the end. Please refer to some other implementations if u still didn’t understand back-prop here.

Let us calculate a few handy derivatives before we actually calculate the
error derivatives wrt weights in this layer.

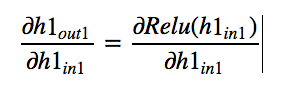
We already know the derivative of relu (We have seen it at the beginning of
the post). Since all inputs are positive, We will get output as 1

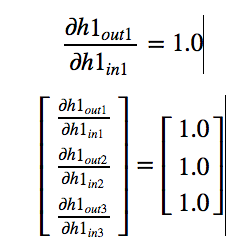
For each input to neuron let us calculate the derivative with respect to
each weight. Now let us look at the final derivative.

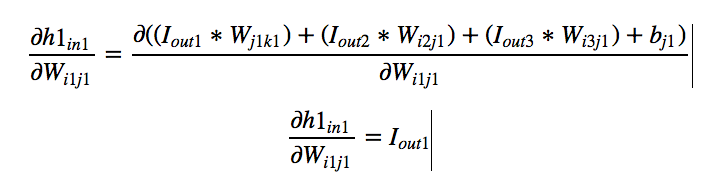
By symmetry we can write,

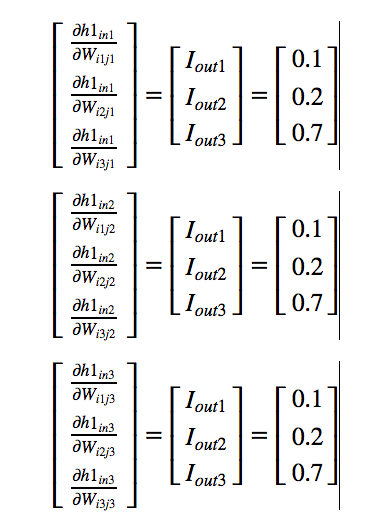
Now we will calculate the change in

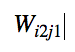
and generalize it to all variables. This will be simply

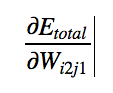
Using chain rule,

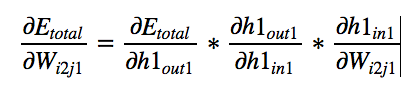
By symmetry,

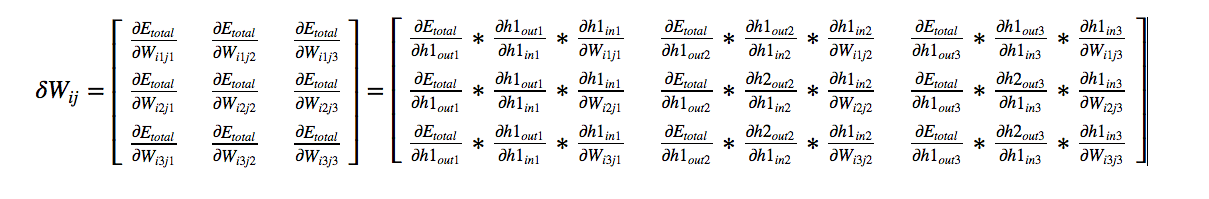
We know the 2nd and 3rd derivatives in each cell in the above matrix. Let us
look at how to get to derivative of 1st term in each cell.

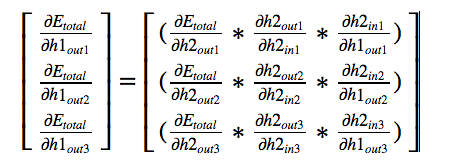
We have calculated all the values previously except the last one in each
cell, which is a simple derivative of linear terms.

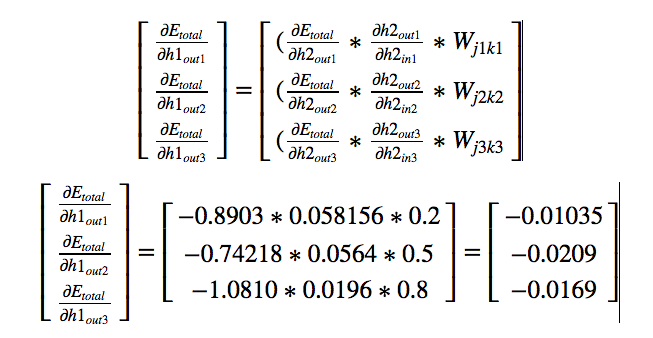
In our example,

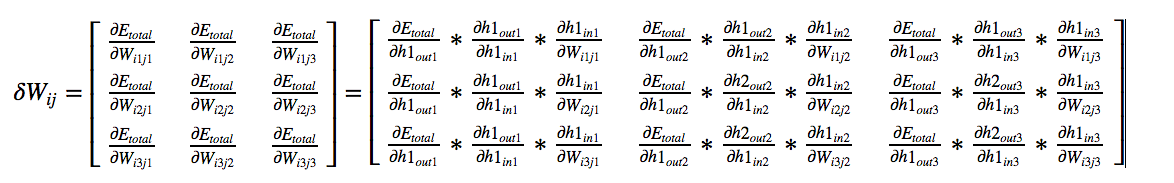

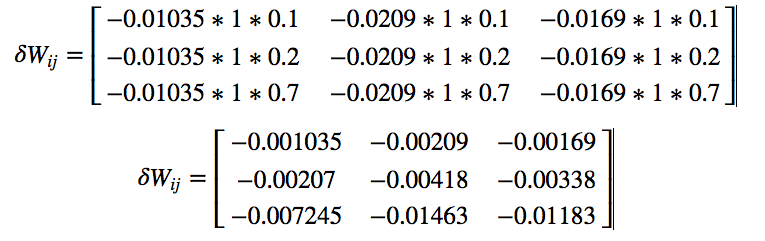
Consider a learning rate (lr) of 0.01 We get our final weight matrix as



The End of Calculations
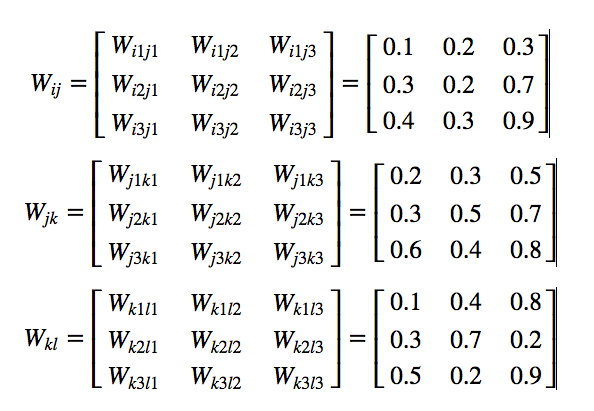
Our Initial Weights:

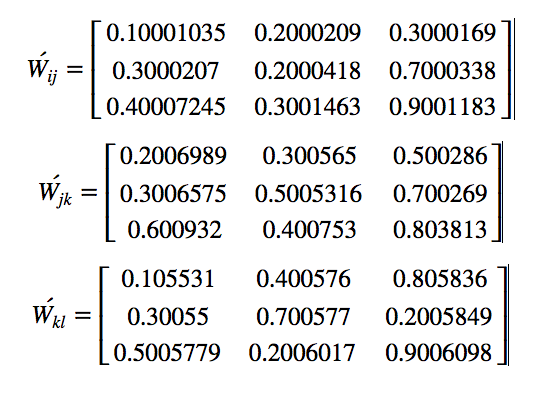
Our Final Weights:

Important Notes:
- I have completely eliminated bias when differentiating. Do you know why ?
- Backprop of bias should be straightforward. Try on your own.
- I have taken only one example. What will happen if we take batch of examples?
- Though I have not mentioned directly about vanishing gradients. Do you see why it occurs?
- What would happen if all the weights are the same number instead of random ?
References Used:
- http://csrgxtu.github.io/2015/03/20/Writing-Mathematic-Fomulars-in-Markdown/
- https://mattmazur.com/2015/03/17/a-step-by-step-backpropagation-example/
- http://eli.thegreenplace.net/2016/the-softmax-function-and-its-derivative/
Code available on Github :
I have hand calculated everything. Let me know your feedback. If you like it, please recommend and share it. Thank you.
