Hoofdstuk 8 Convolutionele Neurale Netwerken (CNN)
8.1 Het onstaan van Computer Vision
Computer vision is een oude discipline die zich bezighoudt met het automatisch interpreteren van onder andere stilstaande beelden en videobeelden. Oorspronkelijk was het doel van deze discipline om digitale beelden te bewerken (eng: image processing) zodat er kenmerken (eng: features) geëxtraheerd konden worden. Een voorbeeld is het ontwikkelen van algoritmen voor het ontdekken van contrasterende randen (eng: edge detection). Voor gezichtsherkenning, bijvoorbeeld, was het idee dat je de ogen van een gezicht kan herkennen aan twee donkere gebieden met daartussen een lichter gebied (van de neus). Hoewel dat inderdaad een logische benadering lijkt te zijn, blijkt dit in de praktijk toch ontoereikend (zie Figuur 8.1).

Figuur 8.1: Negen gezichten. Men kan veronderstellen dat ogen altijd donkerder zijn dan de neus en dus een gemakkelijke manier om het kenmerk ‘ogen’ te onderscheiden. Hier wordt dit idee getest. Met het minimalistisch software-pakket IrfanView werd er ter hoogte van de ogen een selectie van 35 × 434 pixels gemaakt, omgezet naar grijswaarde en getransformeerd met het pixelize-algoritme met parameter 19. Bij een aantal gevallen zie je inderdaad het patroon donker-licht-licht-donker. Aan de meeste andere gezichten, misschien ten gevolge van het dragen van een bril of het bezitten van een andere huidskleur, zie je meteen dat deze procedure ontoereikend is. Deze gezichten werden gegenereerd door het algoritme van Tero Karras Karras et al. 2020. Voor alle duidelijkheid: het gaat hier dus niet om bestaande mensen.
Ondertussen behoort computer vision bijna volledig toe aan de discipline van ML. Inderdaad, met de opkomst van neurale netwerken was er een manier gevonden om de feature selectie-procedure volledig te automatiseren. Een van de belangrijkste vooruitgang in de ontwikkeling van convolutionele NN werd verwezenlijkt door Alex Krizhevsky Krizhevsky et al. 2012. De details van zijn ontdekkingen gaan we in de volgende paragrafen bespreken, maar het is interessant te weten dat de ontdekkingen er gekomen zijn door de natuur na te bootsen, meer bepaald het gezichtsvermogen bij zoogdieren (zie Figuur 8.2).
Persoonlijkheid 8.1 (Alex Krizhevsky)

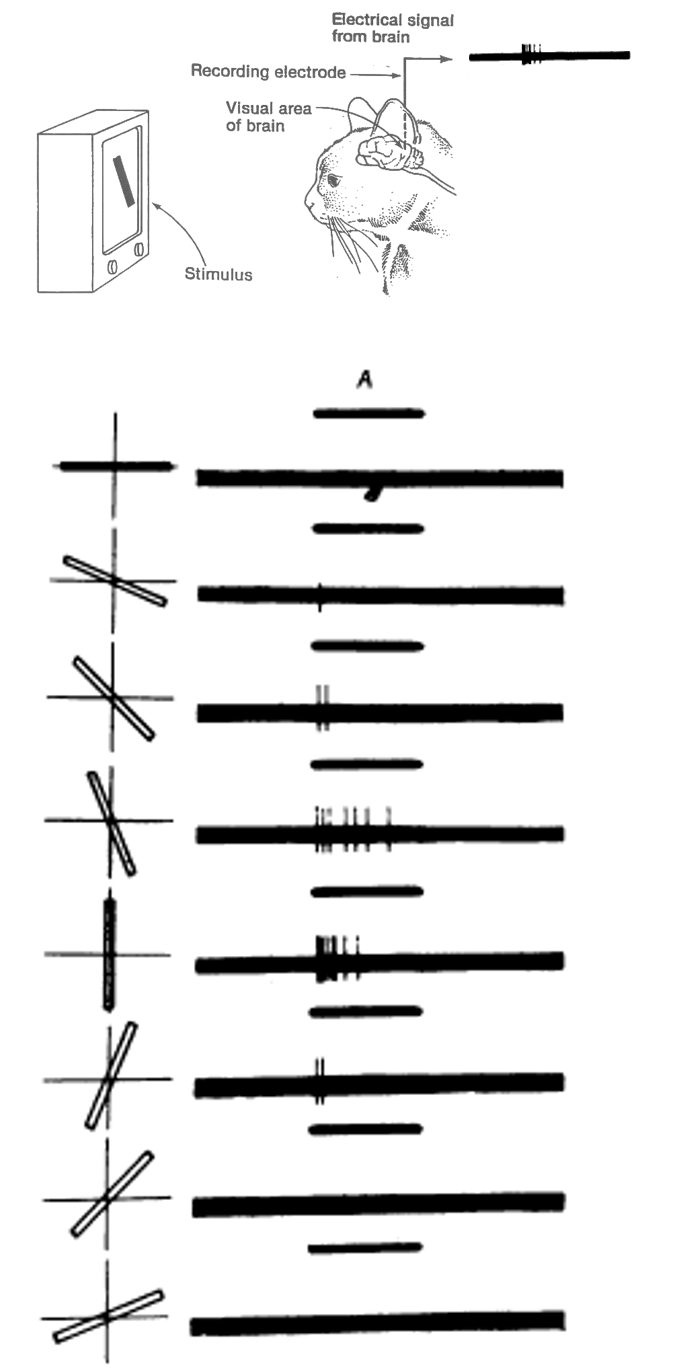
Figuur 8.2: Spraakmakend experiment waarbij werd aangetoond dat sommige neuronen in de visuele cortex van huiskatten (maar dit geldt als model voor ander zoogdieren, waaronder de mens) enkel afgevuurd worden bij het zien van verticale lijnen Hubel and Wiesel 1959.
8.2 Waarom vanilla SGD netwerken ontoereikend zijn
Waarom zouden er voor beeldherkenning nieuwe algoritmen ontwikkeld moeten worden. We zagen eerder in deze cursus dat de cijfers van de MNIST dataset herkend kunnen worden door gebruik te maken van een standaard NN met standaard optimalisatie algoritmen (eng: vanilla SGD, vanilla stochastic gradient descent). Het probleem is de schaalbaarheid. De afbeeldingen van de MNIST dataset bestonden uit 28 pixels × 28 pixels in grijswaarden. De invoerlaag wordt dan al meteen 784 noden groot en het model bestond uit méér dan 100 000 parameters. Bedenk dan hoe groot het netwerk zou moeten worden voor de analyse van 4K video met 3840×2160 pixels aan 60 beelden per seconde.
Het komt erop neer dat de volledige geconnecteerde lagen (eng: fully-connected layers) snel té zwaar worden voor onze huidige computers, een gevaar vormen voor overfitting en algemeen elektron-verspillend zijn. Het aantal parameters moet dus drastisch verlagen om het gebruik van NN voor real-time beeldherkenning mogelijk te maken. Een dropout regularisatie biedt hier onvoldoende soelaas omdat je hiermee te veel informatie negeert en belangrijke patronen mist die zich op kleine schaal manifesteren.
8.3 De CNN Filter
Een van de elementen die convolutionele NN mogelijk maakte was het gebruik van filters. Een filter is een patroon waarmee een input wordt gescand. Laten we Figuur 8.3 grondig onderzoeken. Links wordt een eenvoudige afbeelding voorgesteld met afmetingen 8 pixels × 8 pixels × {0, 1}. Filter 1 stelt een verticale patroon voor, Filter 2 een horizontaal patroon. Tijdens de convolutie-operatie (voorgesteld met de symbolen ∗ of, indien het om circulaire data gaat, \(\circledast\)) worden de filters a.h.w. over de afbeelding geschoven en telkens gecontroleerd in hoeverre de afbeelding op die locatie het patroon vertoont. In deze binaire filter is het resultaat van de convolutie een 1 telkens wanneer het patroon exact overeenkomt en een 0 als het niet perfect overeenkomt.

Figuur 8.3: De demonstratie van een CNN filter. In dit vereenvoudigd voorbeeld gaat het om een ‘binaire’ 2D filter in de zin dat het resultaat van een scan-operatie binaire is en dat de invoer 2-dimensionaal is. Zie tekst voor details. Deze figuur werd aangepast van figuur 5-6 uit Buduma and Locascio 2017.
In onderstaande video zien we de filter in actie. Merk op dat het resultaat van deze filter al iets complexer is zoals voorgesteld met de groene (meer positieve match) en rode kleuren (meer negatieve match; i.e. omgekeerd patroon). Na het toepassen van de filter wordt er een ReLU activatie functie toegepast en later een Pooling (zie later).
Dit is fragment uit de presentatie van Otavio Good tijdens de TheAIConf in 2017
8.4 De filter binnen een NN
Hoe vertaalt dit zich nu naar een neuraal netwerk? In een NN stemt de filter operatie overeen met het meervoudig uitvoeren van inwendige producten tussen invoerlaag en filter-matrix. Het is belangrijk te begrijpen dat de filter gemeenschappelijk is voor de ganse filter-laag. Dat wilt zeggen dat elk neuron van de invoerlaag met dezelfde filter wordt vermenigvuldigd. De convolutie in dit verhaal vertaalt zich als een soort herhalingslus.3

Figuur 8.4: In een NN stemt de filter operatie overeen met het meervoudig uitvoeren van inwendige producten tussen invoerlaag en filter-matrix.
8.5 Filter als compressor
Omdat binnen een laag dezelfde filter wordt gebruikt voor alle inkomende connecties, beperkt men zeer sterk het aantal parameters:

Figuur 8.5: Een enkele filter heeft slechts een beperkt aantal parameters nodig. In werkelijkheid zal het iets meer dan 3 zijn, in dit voorbeeld, zie later in de tekst.
Natuurlijk komt men niet toe met slechts één filter. Het is niet voldoende om enkel horizontale of verticale patronen te herkennen, misschien willen we ook krommen, schuine lijnen en dergelijke…. Het aantal filters neemt dan wel toe, maar niet langer exponentieel met toenemende grootte van de afbeeldingen.
8.6 De stride niet opgeven
Er zijn (hyper)parameters die een filter kenmerken. De eerste die we hier bespreken is de stride (nl: letterlijk de pas; stapgrootte). Het geeft eenvoudigweg aan met welke frequentie de filter operatie moet uitgevoerd worden. Dit is weer een andere manier waarmee een filter het aantal neuronen weet te beperken, maar opgelet. Een stride > 1 betekent dat je onvermijdelijk patronen gaat missen.

Figuur 8.6: De demonstratie van de stride hyperparameter van een filter.
De tweede hyperparameter is de padding. Dit is de ‘dikte’ van de rand met nul-waarden die rond de ‘afbeelding’ van de input laag wordt aangebracht om ervoor te zorgen dat de filter operatie de dimensies niet wijzigt zoals het geval is in Figuur 8.4.
8.7 De volledige filter-laag
De filter-operatie vervangt de traditionele matrix-operatie die eerder aangeduid werd met functie \(g\). De output is echter niet een getal maar een zogenaamde feature map. Dat betekent dat er na de filter operatie nog steeds een activatiefunctie volgt. Dat is vaak een ReLU functie omdat deze de meest eenvoudige niet-lineaire functie is.
8.8 Meerdere filters per laag
Als we meerdere filters kunnen hebben en elke filter genereert een feature map met gelijkaardige dimensies als de vorige laag in het netwerk, dan betekent dit dat de feature maps dus een extra dimensie hebben, i.e. in plaats van lagen (matrices), krijgen we blokken (3-dimensionele arrays).
Bovendien, de filter die hierboven werd voorgesteld, was twee-dimensionaal. Dat is voldoende voor afbeeldingen in grijswaarden zoals de MNIST dataset. Werk je echter met RGB waarden, dan kan je iets bijzonder doen. Je kan een 3D filter definiëren van bijv. 4 pixels × 4 pixels × 3 kleurwaarden en de convolutie doorvoeren als voorheen, alleen nu in de derde dimensie.
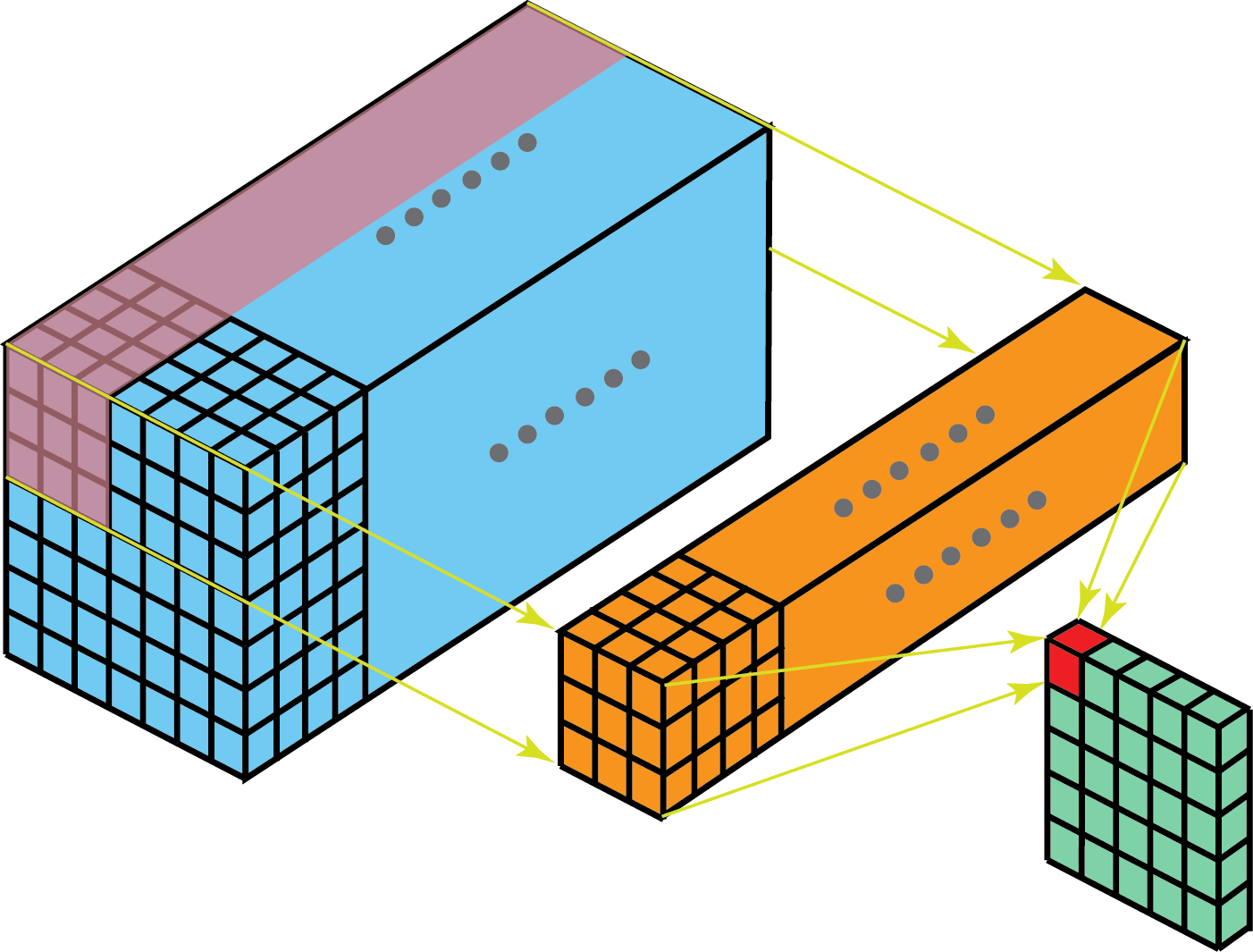
Figuur 8.7: 2D-convolutie met 3D filter. Bron: Kunlun Bai 2019.
We kunnen nu 2D beelden vervangen door 3D beelden (zoals MRI scans of dergelijke) of videobeelden (tijd is dan de derde dimensie) en dan kan de convolutie plaatsvinden 3-dimensies in plaats van 2, men spreekt dan ook van 3D convoluties.
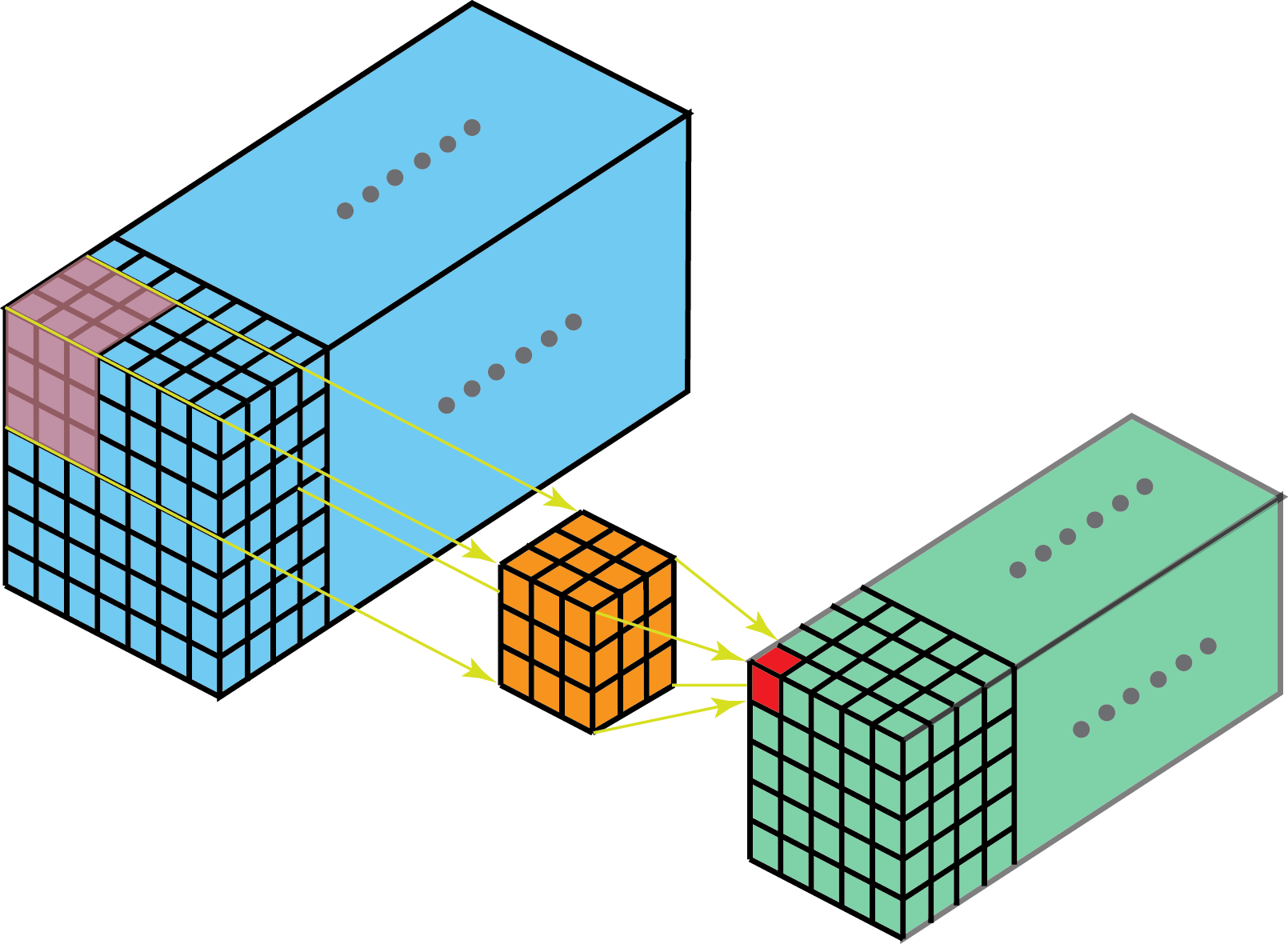
Figuur 8.8: 3D-convolutie met 3D filter. Bron: Kunlun Bai 2019.
8.9 Max Pooling
Hier kunnen we heel kort zijn, dit is letterlijk een soort beeld-compressie, behalve dan dat je telkens de maximum ‘pixel-waarde’ neemt i.p.v. een gemiddelde. Er bestaan dan ook anti-aliasing varianten.

Figuur 8.9: Demonstratie van Max pooling.
Deze operatie wordt, indien beschouwd als onderdeel van een laag, altijd toegevoegd ná de activatiefunctie, We krijgen dus (\(m\) = max pool):
\[x_{out} = m(t(g(x_{in})))\]
Soms wordt deze echter als afzonderlijke laag beschouwd.
8.10 Samenstellen van CNNs
We kunnen nu meerdere lagen samenbrengen in een heus netwerk. Als we begrijpen dat een filter-operatie de informatie probeert te capteren, dat een ReLU-operatie (of andere activatie-functie) de informatie combineert en de max pool-operatie de informatie comprimeert, dan zijn de volgende regels niet al te onlogisch:
- De filter + activatie-functie vormen samen een zogenaamde convolutie laag
- De max-pool laag is niet verplicht
- De max-pool laag kan afzonderlijk voorkomen, zonder voorafgaande convolutie
- De max-pool-laag zal vaak voorkomen na een convolutie laag
- De combinatie van convolutie-laag en max-pool-laag wordt vaak meerdere keren na elkaar herhaald om telkens patronen met toenemende complexiteit te capteren
Nog wat links:
Bronvermelding
Buduma, N., Locascio, N., 2017. Fundamentals of deep learning: Designing next-generation machine intelligence algorithms. " O’Reilly Media, Inc.".
Hubel, D.H., Wiesel, T.N., 1959. Receptive fields of single neurones in the cat’s striate cortex. The Journal of physiology 148, 574.
Karras, T., Laine, S., Aittala, M., Hellsten, J., Lehtinen, J., Aila, T., 2020. Analyzing and improving the image quality of stylegan, in: Proceedings of the Ieee/Cvf Conference on Computer Vision and Pattern Recognition. pp. 8110–8119.
Krizhevsky, A., Sutskever, I., Hinton, G.E., 2012. Imagenet classification with deep convolutional neural networks, in: Advances in Neural Information Processing Systems. pp. 1097–1105.
Kunlun Bai, 2019. A comprehensive introduction to different types of convolutions in deep learning towards intuitive understanding of convolutions through visualizations [WWW Document] [Online; accessed 2020-10-14]. URL https://upload.wikimedia.org/wikipedia/en/5/52/Mark_I_perceptron.jpeg
{kind=link}
De densiteit waarvan sprake is in het hoofdstuk rond Data exploratie is trouwens gelijkaardig aan deze filtering-operatie. In het Engels spreekt men van Kernel Density Estimation en de Kernel stemt overeen met de filter van het CNN. Voor meer informatie over de convolutie, verwijs ik naar Wikipedia↩︎