Hoofdstuk 12 Neurale Netwerken met Extern Geheugen
12.1 Inleiding NN met extern geheugen
Als uitbreiding op de seq-2-seq-type neurale netweken, RNNs en LSTMs is men een aantal jaren geleden beginnen experimenteren met het toevoegen van een soort extern geheugen aan ANNs. Bij de eerder besproken LSTMs netwerken was er reeds sprake van een soort werkgeheugen, maar de bedoeling is hier om het computationeel gedeelde van het ANN beter te scheiden van het geheugen gedeelte. Het gevolg is dat we bijvoorbeeld de grootte van het geheugen kunnen aanpassen zonder de grootte en complexiteit van het netwerk te wijzigen.
Het resultaat van een zelfstandig extern geheugen is de productie van een zelfstandige ‘computer’ die uit voorbeelden kan leren. We bespreken hier twee types netwerken: Neurale Turing Machines (eng: Neural Turing Machines of NTM) en Differentiële Neurale Netwerken (eng: Differential Neural Networks of DNC).

Schrijf- en leeskop van een harde schijf
Bron afbeelding: Eric Gaba onder een Creative Commons Attribution-Share Alike 3.0 Unported licentie
{kind=link}
Persoonlijkheid 12.1 (Alan Turing)

12.2 Neurale Turing Machines
Neural Turing Machines (NTMs) werden bedacht door Google’s DeepMind team (zie Graves et al. 2014). Net als bij LSTM is het doel van NTMs om de lange-termijn afhankelijkheden te capteren. NTMs verschillen echter van eerdere RNN in dat ze zogenaamde aandacht mechanismen (eng: attention mechanisms) gebruiken om het lezen en schrijven naar het extern geheugen efficiënter te laten verlopen. De abstrahering van de architectuur van een NTM vind je in Figuur 12.1.

Figuur 12.1: Architectuur van een Neurale Turing Machine (NTM). Een controller vormt het eigenlijk ANN (bijvoorbeeld een RNN) terwijl de schrijfkop en leeskop (naar analogie met fysieke gegevensdragers) instaan vormt de informatie-overdracht naar het extern werkgeheugen.
Het komt erop neer dat en RNN wordt uitgebreid met het extern geheugen en dit geheugen bestaat uit niets meer dan een tabel of matrix met één herinnering per rij. Een extern geheugen is natuurlijk pas nuttig als je er gegevens uit kunt lezen en nieuwe gegevens kunt in plaatsen.
12.3 Lezen uit en schrijven naar een NTM geheugen
Het ophalen en het manipuleren van het geheugen gebeurt op een probabilistische wijze door gebruik van gewichten. Het principe is als volgt. Stel dat een (voor de eenvoud één-dimensionaal) extern geheugen bestaat uit de rij \(M := (12, 87, 45, 65, 49)\). Ontwikkelaars zijn gewoon om een element uit zulk een rij op te halen door middel van een index, i.e. deterministische wijze: \(M_3 = 45\). In plaats daarvan, gaan we \(M\) als een vector beschouwen en deze vermenigvuldigen met een co-vector \(w := (0, 0.1, 0.7, 0.2, 0)\) die we de aandachtsvector noemen (eng: attention vector), waarbij \(\sum_{i}w_i=1\) (zie Appendix voor uitleg over vectoren, co-vectoren en tensoren). Deze vermenigvuldiging komt overeen met wat je zou kunnen noemen een ‘probabilistische selectie’ of gewogen gemiddelde met de ‘aandacht’ op het derde element uit de rij:
\[ M_w=M^\intercal w\\ =0\cdot12+0.1\cdot87+0.7\cdot45+0.2\cdot65+0\cdot4 \\ =53.2 \]
Waarom zo moeilijk doen?
Stelling 12.1 (Waarom geen discrete selectie van geheugen elementen) De traditionele manier om elementen uit een rij of matrix te selecteren, zoals bij \(M_3\), maakt gebruik van discrete indices (\(M_i\) met \(i \subset {1, 2, ...}\)). Tijdens het leerproces zal de NTM de ideale indices trachten te voorspellen. Willen we echter gebruik maken van het Backpropagation algoritme en van de gradiënt-afdaling waarvan eerder sprake, dan moet deze indices differentieerbaar zijn. Discrete waarden zijn dat niet. Het is immers absurd om zoiets als het volgende te onderzoeken: wat is het effect van een kleine wijziging in de index (bijvoorbeeld van 3 naar 3.0001) op de accuraatheid van de voorspelling? Vandaar de noodzaak om een continue indexering te gebruiken i.p.v. een discrete indexering.
Belangrijke noot: de gradiënt-afdaling is geen verplichting, het maakt een ANN mogelijk eenvoudiger, maar er zijn evenzeer specialisten die vinden dat het blijven vasthouden aan de gradiënt-afdaling eerder een belemmering is en stellen de noodzaak ervan in vraag.
Op het bovenstaande principe zijn de lees- en schrijf operaties ten aanzien van het extern geheugen van een NTM gebaseerd. Het lezen gebeurt a.d.h.v. een aandachtsvector (eng: attention vector) die op een continue wijze een geheugenplaats selecteert (zie Figuur 12.2).

Figuur 12.2: De lees-operatie uit een extern NTM geheugen-matrix. In dit geval is er een ‘focus’ op de 6e geheugenplaats.
Het schrijven is iets complexer. Het bestaat uit twee afzonderlijke operaties. De eerste operatie dient om te vergeten, i.e. om bestaande gegevens uit het extern NTM geheugen te wissen. De tweede operatie dient om nieuwe gegevens te ‘onthouden’. Deze beide operaties zijn veel fijngevoeliger dan de lees-operatie en kunnen op individuele geheugenplaatsen inwerken. Dit gebeurt door een combinatie van een aandachtsvector enerzijds en een wis-vector (eng: erase vector) of schrijf-vector (eng: write vector) anderzijds. Figuur 12.3 laat zien hoe de schrijf-operatie in zijn werk gaat.
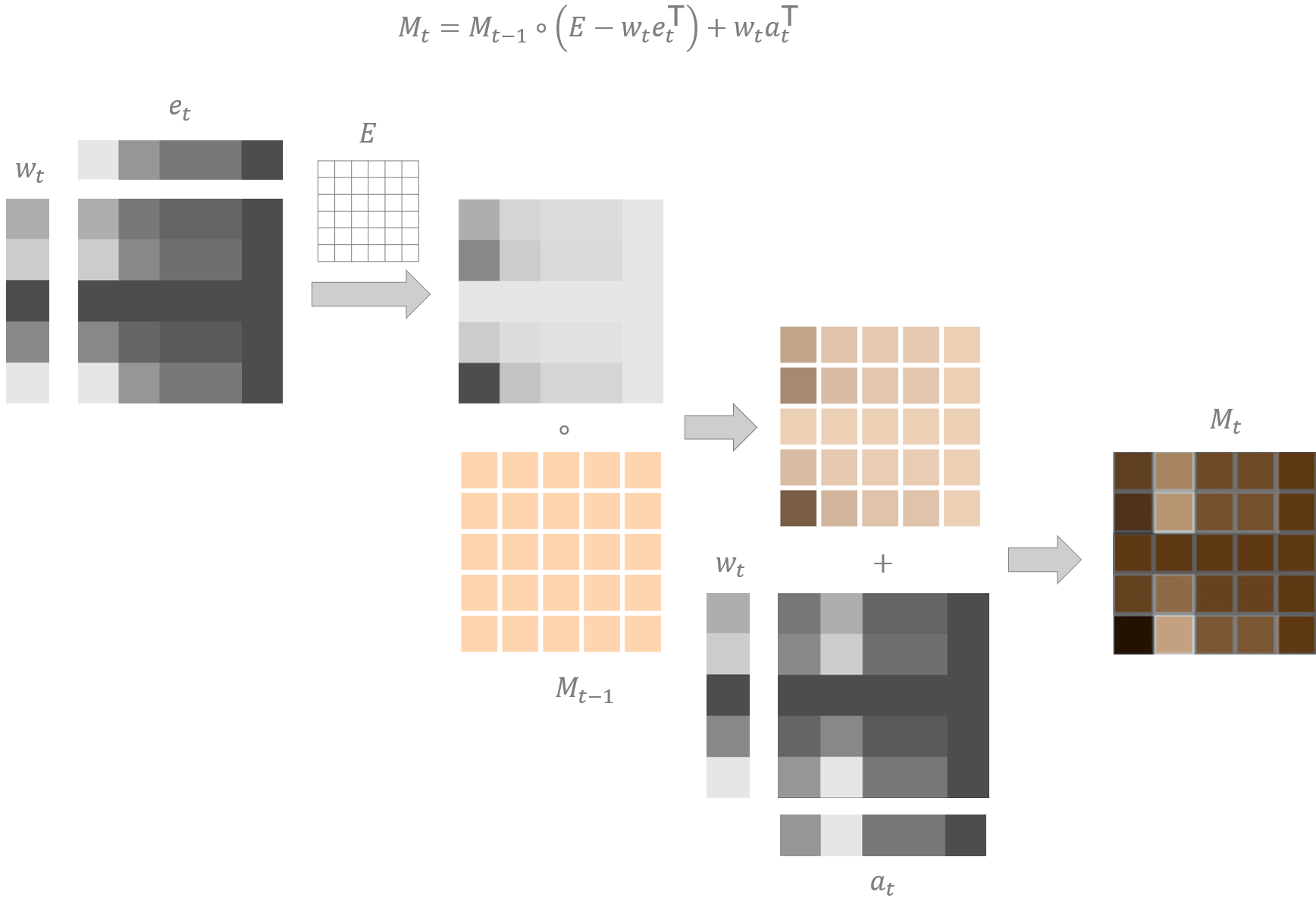
Figuur 12.3: De werking van een schrijf-operatie te aanzien van een extern NTM geheugen. \(E\) is een eenheidsmatrix met gepaste dimensies (een matrix gevuld met enen), \(\circ\) is het Hadamardproduct. Als in de grijswaarde matrices lichte vlakken hogere waarden voorstellen, dan komt de weergegeven schrijf-operatie overeen met het wissen van de waarde in cel (5, 1) en het verhogen van de waarde in cel (5, 2). Tinten van oranje zijn hier eerder indicatief en niet als exact te interpreteren.
12.4 Adressering van NTM geheugens
Het adresseren van een NTM geheugen kan op twee manieren plaatsvinden.
- Op basis van locatie: Dit is de methode waarop in vorige paragraaf werd gealludeerd, namelijk het selecteren van een geheugenplaats op basis van een index.
- Op basis van inhoud: Er is echter nog een tweede manier nog om een Turing machine te ontwerpen, namelijk het selecteren van een geheugenplaats op basis van zijn inhoud.
12.5 Inhoud-gebaseerde adressering
De controller van een NTM kan leren om een geheugenplaats (een rij binnen de geheugen matrix) terug te vinden dat zo goed mogelijk overeenstemt met een vooropgestelde sleutelvector \(\mathbf{k_t}\) (eng: key vector). Hiervoor wordt de aandachtsvector als volgt berekend:
\[ w_t^c=\frac{\exp\left(\beta_t\mathscr{D}\left(M_t,\mathbf{k_t}\right)\right)}{\sum_{i=0}^{N}\exp\left(\beta_t\mathscr{D}\left(M_t,\mathbf{k_t}\right)\right)} \]
, waarbij \(\beta\) hier voor een vermenigvuldigingsfactor staat (eng: key strength) en waarbij \(\mathscr{D}\) voor een afstand-functie staat (eng: similarity function). Voor \(\mathscr{D}\) wordt meestal de cosinusgelijkenis genomen. Je zal merken dat bovenstaande vergelijking erg lijkt op de softmax en inderdaad, het komt neer op een genormaliseerde versie van de softmax. De parameter \(\beta\) is geen hyperparameter. Het wordt door de controller aangeleverd en aangeleerd. Een hogere waarde voor \(\beta\) zal ervoor zorgen dat een onbesliste sleutel-vector (tot bijna het extreme geval van een eenheidsvector) toch een duidelijk gefocusseerde aandachtsvector oplevert.
12.6 Locatie-gebaseerde adressering
Deze adressering moet toelaten dat de controller aanleert om bepaalde geheugenplaatsen op te roepen en om te navigeren naar een naburige geheugenplaats. Dit gebeurt door op de aandachtsvector een rotationele convolutie uit te voeren (i.e. filter operatie) met een zogenaamde shift weighting \(\mathbf{s_t}\):

Figuur 12.4: Voorbeeld van een convolutionele shift-operatie om de focus één plaats naar onder te verschuiven. Merk op dat dit een cyclisch gebeuren (vandaar rotationele convolutie) is in de zin dat de cel van de aandachtsvector \(w_t\) die a.h.w. van de vector valt bovenaan wordt gerecycleerd (i.e. \(\widetilde{w}_{t,1} = w_{t, 6}\)).
12.7 Adresseringsmechanisme
Hier volgt een beschrijving van het volledig adresseringsmechanisme.

Figuur 12.5: Overzicht van het adresseringsmechanisme. Zie tekst voor meer uitleg.
Zoek een geheugenplaats op basis van de sleutelvector \(\mathbf{k_t}\) en de vermenigvuldigingsfactor \(\beta\)
Interpoleer de resulterende aandachtsvector \(w_t^c\) met de aandachtsvector \(w_{t-1}\) van het vorige tijdstip:
\[ w_t^g=g_t w_t^c + (1-g_t)w_{t-1} \]
, waarbij \(g_t\) en \(w_t^g\) de interpolation gate en de gated weighting zijn
In deze stap kan de controller aanleren om zich te verplaatsen in het geheugen (i.e. locatie gebaseerde adressering)
Om te voorkomen dat als gevolg van voorgaande filter operatie er een vervagingseffect optreedt (eng: blurring effect), wordt er een verscherping-operatie uitgevoerd door de aangeleerde verscherpingsfactor \(\gamma_t\) die ook door de controller wordt beheerd. De formule voor de verscherping is als volgt:
\[ w_t=\frac{\tilde{w}_t^{\gamma_t}}{\sum_{i=0}^{N}\tilde{w}_{t, i}^{\gamma_t}} \]
12.8 De nadelen van NTMs
De uitvinding van NTMs was zonder meer revolutionair, maar toch bleken er al snel een aantal gebreken te bestaan.
- Omdat het hele mechanisme om informatie weg te schrijven naar het extern geheugen differentieerbaar moest zijn treedt er ook vaak interferentie op waarbij de weggeschreven informatie enigszins overlapt met eerder weggeschreven informatie. Zeker wanneer de aandachtsvector onvoldoende gefocusseerd is, treedt dit fenomeen op.
- Er is ook een probleem met het overschrijven van data. Typisch zal de controller aanleren om nieuwe data te plaatsen in een vrije locatie van het extern geheugen terwijl soms het overschrijven van bestaande informatie een voordeel biedt
- De controller zou moeten kunnen aanleren om een sprong te maken in het extern geheugen, daar een bepaalde operatie uit te voeren en daarna terug te springen naar de oorspronkelijke locatie. De controller mist deze vaardigheid omdat hij geen kruimelspoor bijhoudt.
Deze beperkingen werden door dezelfde auteurs onderzocht waarop ze met een verbeterde versie kwamen voor de NTM: de differentiële neurale computer (eng: Differentiable Neural Computer of DNC; zie Graves et al. 2016).
12.9 De differentiële neurale computer

An artist’s impression of Google’s Differentiable Neural Computer © Google DeepMind
Bron afbeelding: Adam Cain, een artist bij het DeepMind team.
We gaan ons hier niet verder verdiepen in de architectuur van een DNC, maar ik geef toch even mee wat de verschillen zijn t.o.v. een NTM:
Stelling 12.2
DNC versus NTM:
- De DNC heeft meerdere leeskoppen
- De DNC werkt met een interface vector waarin a.h.w. de query vervat zit om de lees- en schrijf-opdrachten uit te voeren
- De DNC maakt gebruik van een link matrix, een voorrangsvector (eng: precendence vector) en een gebruiksvector (eng: usage vector).
Samengevat komt het er enerzijds op neer dat er bij het combineren van lees- en schrijf-operaties en voldoende geheugen-beheer moet plaatsvinden om problemen rond overlap te voorkomen. Anderzijds was het ook de bedoeling dat DNCs in staat zijn om te onthouden in welke volgorde eerder informatie werd weggeschreven naar het geheugen.

Figuur 12.6: Overzicht van de architectuur van aan DNC.
De link matrix en de gebruiksvector vormen een onderdeel van een zogenaamde vrije lijst (eng: free list) data structuur die de controller instaat stelt om zelf te beslissen om een bepaalde geheugenplaats toegekend moet worden of niet.
12.10 Implementatie DNC
Hiervoor kijken me naar een video-clip van DeepMind zelf. Het laat zien hoe een DNC ons in staat stelt om eerdere onoplosbare vraagstukken te laten oplossen:
DNC zijn instaat om allerlei vragen te beantwoorden over een graaf-gestructureerde gegevens zoals sociale netwerken, parse-trees, knowledge graphs en dergelijke zelfs als de gegevens in een lineaire vormen worden gevoed aan het algoritme.
In een ander voorbeeld, dat gerelateerd is met het aanleren van concepten (denk aan het concept ‘boom’ uit de eerste les), wil men bijvoorbeeld een ANN het volgende ‘raadsel’ proberen oplossen:
Alice gaat naar de keuken, alwaar ze een glas melk neemt. Onderweg naar de living neemt ze een appel uit de fruitmand.
Vraag: Hoeveel objecten heeft Alice bij zich?
Het lijkt verschrikkelijke overkill om hiervoor zulk een complex netwerk op te zetten. Maar wat als je niet op voorhand weet welke vraag er gesteld gaat worden?
Bronvermelding
Graves, A., Wayne, G., Danihelka, I., 2014. Neural turing machines. CoRR abs/1410.5401.
Graves, A., Wayne, G., Reynolds, M., Harley, T., Danihelka, I., Grabska-Barwińska, A., Colmenarejo, S.G., Grefenstette, E., Ramalho, T., Agapiou, J., others, 2016. Hybrid computing using a neural network with dynamic external memory. Nature 538, 471–476.