Hoofdstuk 5 Manipuleren van data
Hieronder volgt een korte samenvatting van een aantal vaak gebruikte transformaties. Waarom zou je data willen transformeren. Hier staan een aantal redenen opgesomd:
- Om duidelijkheid te scheppen en de data leesbaarder te maken voor mensen
- Om de data voor te bereiden voor statische analyse
- Om nieuwe variabelen te creëren (eng: feature engineering)
- Om eenvoudiger gedistribueerd en parallel te kunnen programmeren
- Om de data te standaardiseren volgens CDMs (common data models) van het bedrijf (zoals voor een EDM Enterprise Data Model) of van een discipline (zoals CDISC standaarden in de klinische wereld)
- Om de data te onderworpen aan de regels van een bepaalde type opslag software. Wil je bijvoorbeeld de analyse dataset bewaren in een relationele databank, dan zal je rekening moeten houden met de regels rond primary, surrogate en foreign keys.
5.1 Kort overzicht van de manipulaties
5.1.1 Filteren en versnijden
Het versnijden (eng: slicing) is hier te interpreteren in de betekenis van aan stukken van een bepaalde vorm snijden en niet bijvoorbeeld in de betekenis van aanmengen met iets van mindere kwaliteit. Het komt er op neer dat er een selectie van variabelen en instanties gemaakt wordt.

Figuur 5.1: Schematisch overzicht van het versnijden van een dataset.
Denk eraan dat het selecteren van van variabelen een courante activiteit is, terwijl het selecteren van instanties eerder zeldzaam is.
Dus voorzichtig heid geboden. Maar in sommige gevallen is het verantwoord om ook instanties uit de dataset te filteren (eng: subsetting):
- De data bevat uitlopers die verantwoord kunnen worden of die zonder twijfel veroorzaakt worden door een foutieve invoer
- De combinatie van sommige variabelen voor een bepaalde instantie is heel waarschijnlijk foutief en is niet het gevolg van structurele maar eerder van eenmalig fouten in de dataset of het invoer-proces
- Een instantie bevat een combinatie van variabele waarden die de privacy van één of meerdere personen in het gedrang brengt
rode_wijn <- fread("https://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-red.csv")
rode_wijn[, `residual sugar`] %>%
density %>%
plot (main="Residual sugar (g/L)")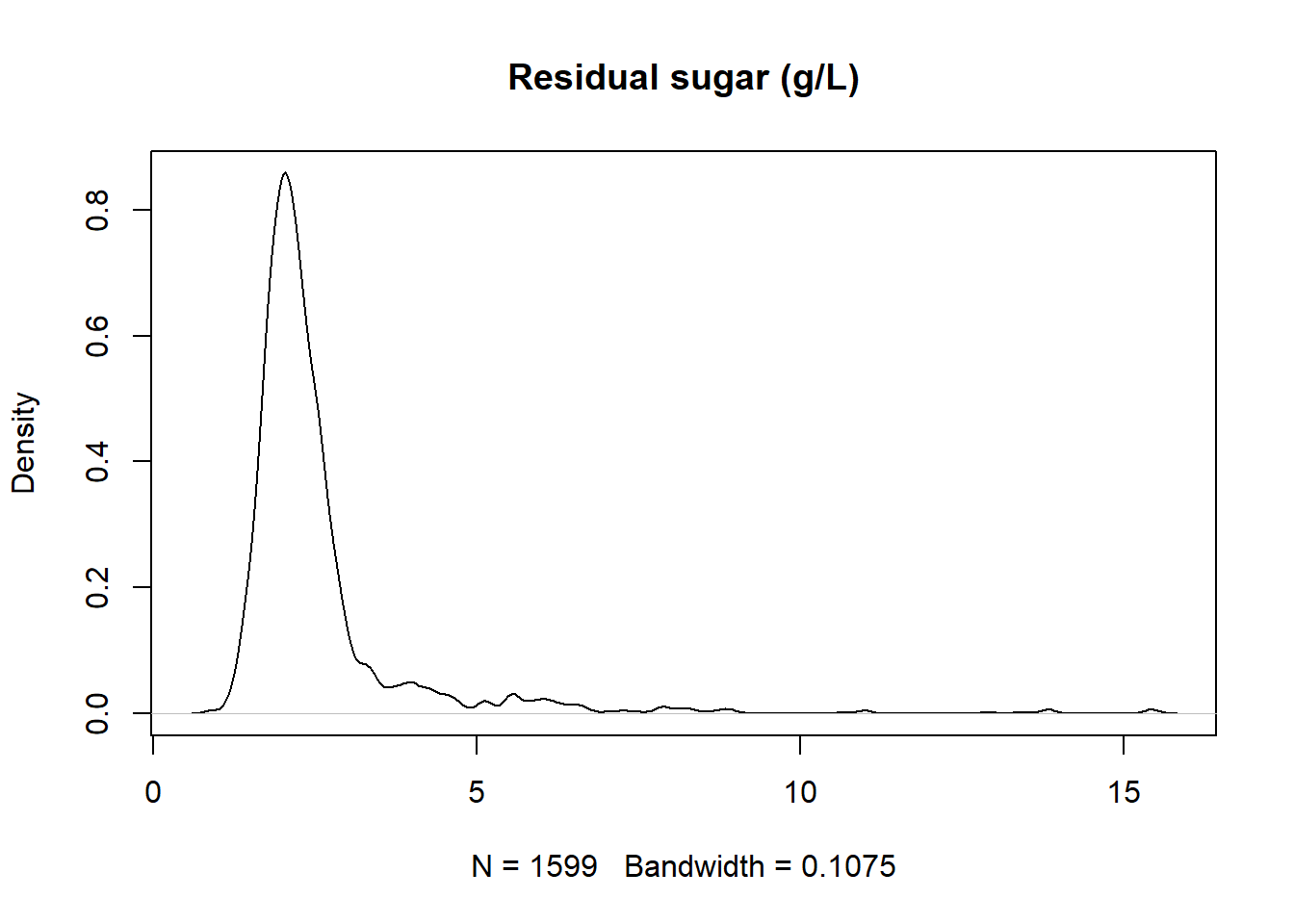
Stel dat rode wijn met een suikergehalte boven de 10g/L wordt afgedaan als fruitsap, dan zou je er van uit mogen gaan dat er een aantal uitlopers zijn, zo halen we ze eruit:
aantal_uitlopers <- rode_wijn[`residual sugar` > 10, .N]
rode_wijn_echt <- rode_wijn[`residual sugar` < 10]
rode_wijn_echt$`residual sugar` %>%
density %>%
plot (main="Residual sugar (g/L)",
sub = paste("Excluding", aantal_uitlopers,
"'outliers' above 10g/L"))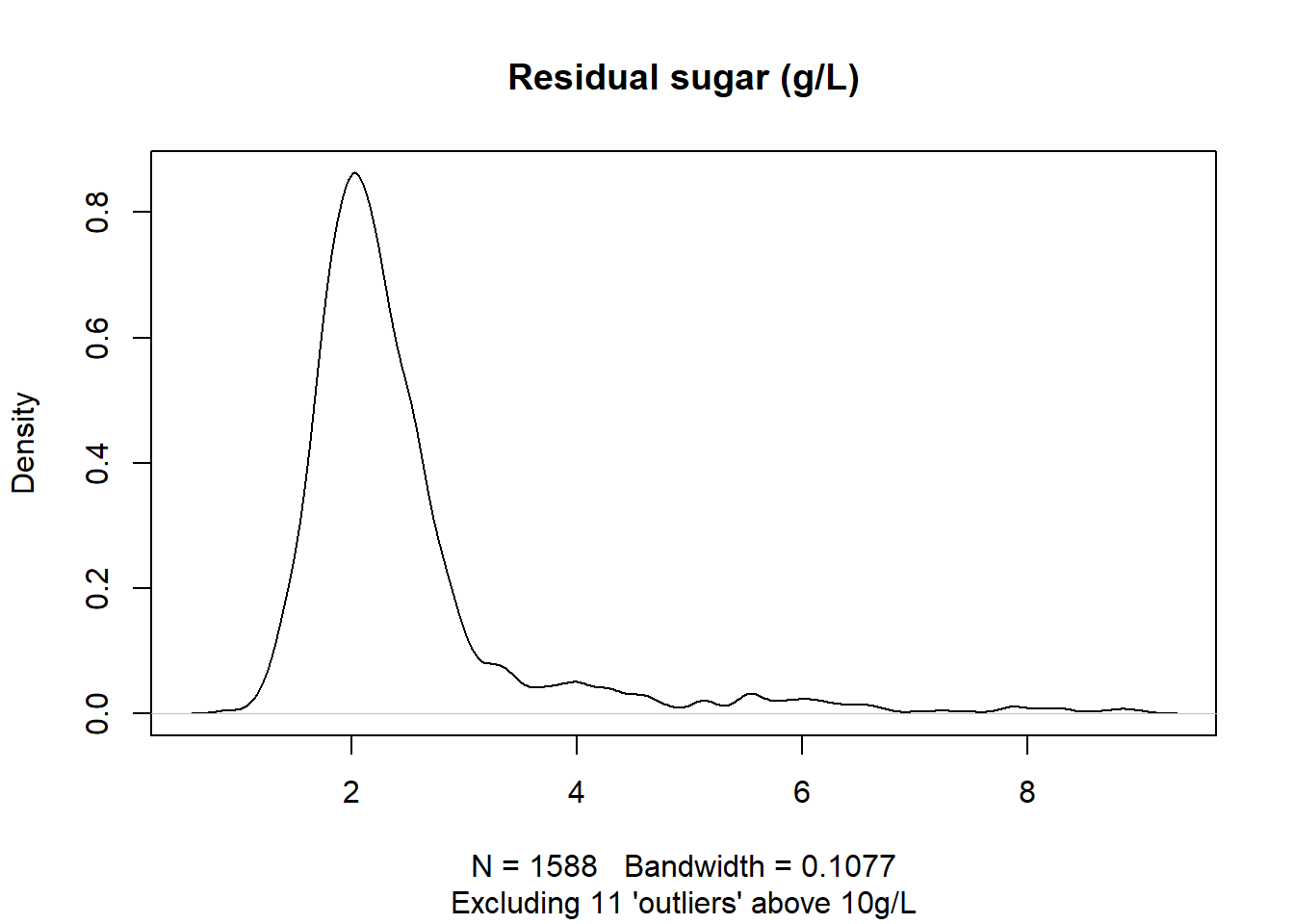
5.1.2 Booleaans masker
Een booleaans masker is gewoon een vector of lijst van booleaanse waarden die gebruikt kunnen worden om uit data frames en data tables die rijen te selecteren die overeenkomen met TRUE in het masker.

In het Voorbeeld 5.1 werd er reeds van een masker gebruik gemaakt:
## [1] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE
## [18] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE FALSE
## [35] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE5.1.3 (Eng.) Grouping and Aggregation
Upon Grouping the data table according to one or more features, the other variables need to be aggregated en this can be done using:
- Selection (first, last, second value, …)
- Measures of central tendency (mean, median, …)
- Measures of dispersion (variance, range, standard deviation, IQR, …)
- Extremes (min, max)
- Counts (Count, unique count, sum, majority vote, counts of missing values, …)
5.1.4 (Eng.) Transforming text
| Transformation | Example | Possible justification |
|---|---|---|
| Change Encoding | UTF16 → UTF8 |
Avoid software incompatibilities |
| Change Casing | "tfr523" → "TFR523" |
Avoid confusing and allow for proper comparison |
| Trim | " TFR523" → " TFR523" |
Ensure proper identification & comparison |
| Add Leading zeroes | "653", "61", … → "0653", "0061", … |
Avoid str/num confusion by humans and machines |
| Add prefix | "0653" → "UHR0653" |
Avoid confusion with other IDs |
5.1.5 (Eng.) Re-Scaling Numerical Values
Here are some of the countless different types of re-scaling:
- Logarithm
- Logit-transform
- Normalization to a fixed maximum value
- Standardization (to a mean of 0 and a variance of 1)
- Division by another field (e.g.
Quantity_By_Month / Days_Per_Month,Revenue_By_Store / Sold_By_Store,Quantity / Weight_Per_Unit, …) - Multiplication (e.g.
Quantity x Unit_Price,Quantity x Unit_Cost) - Subtraction (e.g.
Sales_value – Sales_cost)
{kind=link}
{kind=link}
5.1.6 (Eng.) Discretizations
Is going from continuous data to more discrete data. Here are some examples:
{kind=link}
{kind=link}
Mind that discretization always leads to loss of information.
5.1.7 (Eng.) Information Content
The information of a feature or an entire data set can be measured using indices such as the Shannon Entropy or the limiting density of discrete points.
5.1.8 (Eng.) Reformatting, Type Conversion, Casting or Coercion
Examples:
- String to Integer or vice versa
- Reformatting date to ISO-8601 (
"07/04/2008→"2007-07-04" (YYYY-MM-DD))
5.1.9 (Eng.) Changing numerical Values
Far more invasive then re-scaling is when the data is changed based on some custom algorithm. An example hereof is the removal of a drift in the data (de-trending). Similarly, seasonal effects in time series data can be compensated away. Such changes can obviously impact the outcome of the analysis significantly and needs thorough justification.
5.2 (Eng.) Changing Category Names
This is sometimes called recoding or refactorization and only affects nominal features. It serves to adhere to EDM, to the standards of the DWH and to ensure compatibility across data sets. Alternatively, it simply ensures that misspelled category names are being corrected and alternative spellings are being merged.
5.3 (Eng.) Imputation
Imputation is the completion of missing data. Depending of the patterns the ‘holes’ in the data display or on prior knowledge, separate techniques exist to fill in the blanks.
5.4 Onbehandeld
De volgende onderwerpen werden niet behandeld, ik hoor het graag als jullie individueel of als groep hier meer over willen leren:
- Anonimiseren en pseudonimiseren