Hoofdstuk 14 Rapporteren
14.1 Vormen van schriftelijke communicatie
De vormen van schriftelijke communicatie die relevant zijn voor ML worden in 14.1 weergegeven. Afhankelijk van wat het doel van de communicatie is, wie het publiek is en hoe formeel de communicatie moet zijn kan je een bepaalde vorm kiezen.
Naar een breed publiek toe kan een tutorial schrijven aan externe peers (i.e. buiten de organisatie) om andere wegwijs te maken je specifieke problemen succesvol heb weten afhandelen. Is jouw oplossing echt vernieuwend, dan kan je overwegen om een wetenschappelijk artikel te schrijven.
Is de communicatie gericht naar de klanten en dient deze vooral om het gebruik van de het afgewerkt product toe te lichten (denk bijvoorbeeld aan een site waarin de kans op hartfalen wordt voorspeld aan de hand van allerhande parameters) dan is een handleiding het meest aangewezen. In een handleiding ben je meestal niet erg technisch maar zul je toch de voorspellingen moeten kunnen verklaren en dat is zeker niet altijd voor de hand liggend.
Blijft het binnen de organisatie en is het gericht aan hiërarchisch gelijken (i.e. op ongeveer dezelfde ‘hoogte’ binnen het organigram), dan spreekt men van laterale communicatie binnen de organisatie. dan hangt het af of het werk ge-reviewed moet kunnen worden door een of ander controlerend orgaan (Fagg, Volksgezondheid, CE-markering, …). Zo ja, kan het zijn dat er strikte regels nageleefd moet worden aangaande de vorm en de inhoud van zulke documenten. Typisch gaat het dan om standaard operationele procedures (eng: Standard Operating Procedures of SOPs) voor het verspreiden van guidelines binnen de onderneming.
Is er geen sprake van een controlerend orgaan, dan spreekt men van technische documentatie. Inhoudelijk is dit ongeveer hetzelfde als een SOP, maar er is meer vrijheid qua vorm. Het verschil met een tutorial is dat je hier bepaalde procedures uitlegt over het gebruik van het algoritme in productie zoals bijvoorbeeld voor het opzetten, trainen en optimaliseren (d.m.v. hyperparameters) van het model.
Tenslotte is er nog de mogelijkheid om verticaal binnen de organisatie te communiceren, dit betekent meestal naar boven binnen het organigram. Zowel een verslag als een presentatie komen hier in aanmerking, al is een presenteren uiteraard niet beperkt tot deze situatie, je kan ook naar je collega’s presenteren (naar een breed publiek werkt dit wat minder, zeker in de traditionele PPT-stijl). Dankzij Markdown kan deze twee vaak samennemen en kan je gewoon rechtstreeks het verslag presenteren nadat je het *.md-bestand als *.html of *.pdf hebt omgezet.

Figuur 14.1: Een classificatie van de verschillende vormen van schriftelijke communicatie voor ML projecten.
In dit hoofdstuk gaan we ons beperken tot het schrijven van een een verslag aan een overste binnen de organisatie. Zulk een verslag of rapport kan immers een uithangbord zijn! Om alles een beetje te kaderen, zullen we de flow van informatie volgen van de rapportering binnen het groter geheel van een ML project: van ideatie tot publicatie.
14.2 De vraagstelling
Het is goed om een AI te beginnen met een vraag, dit kan een onderzoeksvraag zijn of een business-vraag. Een vraag naar een AI oplossing komt gewoonlijk van een overste of van elders binnen de organisatie. Je kan natuurlijk ook zelf een vraag bedenken. Het allerbelangrijkste is om de vraagstelling expliciet bekend te maken en te laten goedkeuren door alle belanghebbenden. Inderdaad, de meest voorkomende fout binnen AI: iets onderzoeken dat achteraf (gedeeltelijk) irrelevant blijkt te zijn.
Hier is een voorbeeld van een onderzoeksvraag:
Wat zijn de factoren die de impact van de coronamaatregelen het meeste beïnvloeden?
Stelling 14.1 (Een goede vraagstelling) Een goede vraagstelling bevat de volgende elementen:
- Een vraag en dus altijd met een vraagteken op het einde
- Een (impliciete) doelstelling die functioneel maar niet technisch van aard is
- De veronderstelling van ongelimiteerde hulpbronnen (tijd, geld, mensen, data, …)
Het laatste puntje van Stelling 14.1 komt er dus op neer dat je nooit kan voldoen aan de vraag (een beetje zoals de doelfunctie \(f\)). Het doel is natuurlijk om zo goed als mogelijk aan de vraag te beantwoorden (een beetje als \(\hat{f}\)).
14.3 De probleemstelling
De vraagstelling zelf is natuurlijk niet voldoende. Je moet ook door en door begrijpen waarom je iets wil onderzoeken. Dit ‘waarom’ kan je schrijven als een probleemstelling en komt in de inleiding van je rapport. Je denkt misschien dat de lezer van je rapport goed weet waarom het onderzoek wordt uitgevoerd, en dat is inderdaad meestal zo. Alleen hebben vaak verschillende belanghebbenden daar toch een andere mening over. De motivatie voor het onderzoek kan een belangrijke impact hebben op de werkwijze van een AI project, dus is het goed dat er een consensus bestaat over de probleemstelling alvorens het eigenlijke werk wordt aangevat.
14.4 Uitvoering AI project
De rest van het rapport Nadat de vraagstelling duidelijk is geworden kan men beginnen met het project uit te voeren. De vorige hoofdstukken in deze cursus handelden voornamelijk over hoe je neurale netwerken kunt gebruiken om een antwoord te bieden op de oorspronkelijke vraag. De output van het AI project ziet er altijd als volgt uit:
- Een gepubliceerd model dat in staat is om voorspellingen te doen
- De performantie van het gepubliceerd model
- Informatie over de trainingsfase van het model
Het is deze output die als invoer dient voor het rapport.
14.4.1 Reproduceerbare willekeur
Tijdens je onderzoeksfase moet je zorgen voor het gebruik van seeds telkens wanneer er (pseudo-)willekeurige getallen worden gegenereerd. Een seed is meestal een natuurlijk getal dat door de onderzoek zelf gekozen wordt en dat aangeeft waar in de lijst van pseudo-willekeurige getallen de afnamen ervan begint. Een bepaalde seed zorgt er steeds voor dat dezelfde reeks van willekeurige getallen wordt gegenereerd, Dit is belangrijk voor het verzekeren van de reproduceerbaarheid van het onderzoek (later in dit hoofdstuk meer hierover). In R doe je dit zo:
## [1] 0.9148060 0.9370754 0.2861395 0.8304476 0.6417455 0.5190959 0.7365883
## [8] 0.1346666 0.6569923 0.7050648In Python gebeurt dit zo:
## array([0.37454012, 0.95071431, 0.73199394, 0.59865848, 0.15601864,
## 0.15599452, 0.05808361, 0.86617615, 0.60111501, 0.70807258])Beide talen gebruiken standaard het zogenaamde Mersenne Twister algoritme. Toch valt het op dat de getallen verschillend zijn. Als dat een probleem is, kan je vanuit Python dezelfde c code aanroepen waar R van gebruik maakt, of nog gemakkelijker, laat R de getallen generen en importeer ze in Python. Nog een alternatief om in meerdere talen dezelfde getallen te genereren is het gebruiken van externe websites zoals https://www.random.org/integers/ waar je door middel van een eenvoudige oproep de getallen kunt bekomen:
scan(paste0(
"http://www.random.org/decimal-fractions/?",
"num=10&dec=7&col=1",
"&format=plain&rnd=id.xyz"))## [1] 0.9647914 0.3004568 0.1749213 0.1645292 0.2127342 0.1077416 0.1755337
## [8] 0.2509933 0.8611974 0.9328541Nerd alert 14.1 (Diggin’ deeper) In RStudio kan je de c-code van interne functies achterhalen. Laten we de functie set.seed als voorbeeld nemen. Geef de naam van deze functie, zonder haakjes, in in de console. Je ziet dan de inhoud van de functie. Sommige functies zijn verborgen en dan moet je de namespace opgeven (base::set.seed of zelfs base:::set.seed). Op de laatste lijn code zie dat een interne C functie wordt aangeroepen:
.Internal(set.seed(seed, i.knd, normal.kind, sample.kind))Je kan uitzoeken waar de oorspronkelijke C code zich bevindt door de opdracht:
pryr::show_c_source(.Internal(set.seed(seed, i.knd, normal.kind, sample.kind)))src/main subfolder van de broncode van R, vind je dan het bestand RNG.c waarbinnen de methode do_setseed (SEXP call, SEXP op, SEXP args, SEXP env) staat.
In R, zoals dat vaker gaat, heb je veel meer mogelijkheden dan in Python. Geef ?set.seed op voor meer info.
14.4.2 Tools
Net als in elk vak is het belangrijk om even te blijven stil staan bij de software tools die je gebruikt om je analyse uit te voeren. Zowel Python als R bieden notitieboek (eng: notebook) oplossingen met een breed scala aan pakketten/modules (zie ook de Appendix). Maar er bestaan nog tal van andere oplossingen. Hier is een lijstje met een aantal kenmerken waar je op kan letten bij je keuze van de juiste software:
- Er is een brede community die de software gebruikt en die via gemeenschappelijke ontwikkelingsplatformen (GitHub, Stack Overflow, …) hulp kunnen bieden
- Al de code is Open Source, dit laat toe om, eens je de software wat beter beheerst, te controleren of wat je denkt dat het doet dat ook werkelijk doet
- Ondersteunt het notitieboek principe van ontwikkelen zodat de code geïntegreerd wordt in de schriftelijke communicatie van de resultaten
- Ondersteunt multi-threaded en multi-proces programmatie om zwaardere taken aan te kunnen
- Bevat of wordt ondersteunt door professionele IDE’s om vlot te kunnen ontwikkelen, aan versiebeheer te doen e.d.
- Ondersteunt multi-language programming om de krachten van meerdere programmeertalen te combineren
Misschien is hier de juiste plaats om aan te geven dat er ook tools zijn die niet aan deze voorwaarden voldoen en desondanks nog altijd populair zijn. Het meest prominent voorbeeld hiervan is Microsoft Excel. Excel is als spreadsheet in vele opzichten revolutionair, maar wordt al te vaak misbruikt voor wat het eigenlijk niet dient. De fout ligt dus deels aan de gebruiker (die zijn tools beter moet uitkiezen) en deels aan het Excel ontwikkel team dat ondanks veelvuldige vragen uit de academische wereld halsstarrig misleidende of foutieve functies jarenlang is blijven voorzien (Pottel 2003, Mélard 2014).
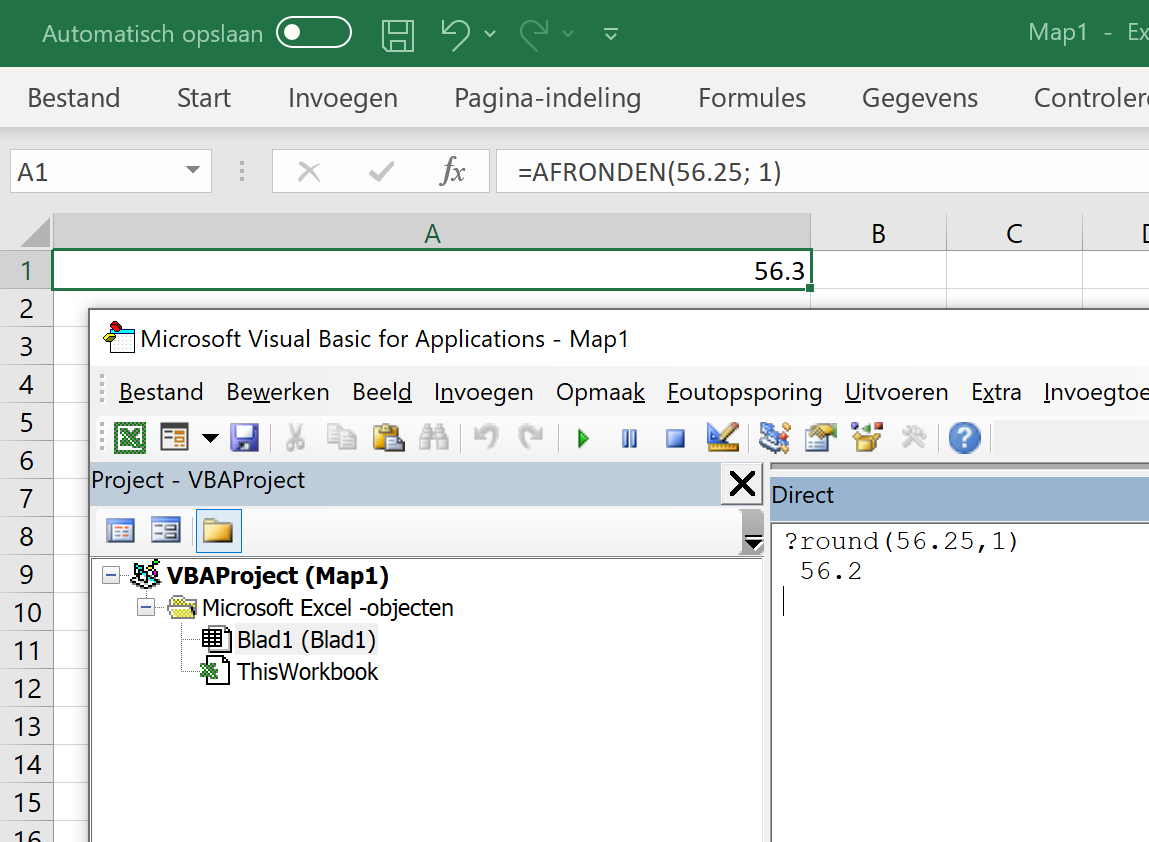
Figuur 14.2: Een voorbeeld waarom je Microsoft Excel zoveel mogelijk moet vermijden (zie het juiste resultaat onder § Beduidende cijfers).
14.5 De inleiding van een rapport
Nadat de probleemstelling en de vraagstelling aan bod zijn gekomen en nadat het project is uitgevoerd, kan je aan de inleiding schrijven.
Stelling 14.2 (Inhoud inleiding) Een goede inleiding bevat de volgende elementen:
- Probleemstelling
- Vraagstelling
- Bondige omschrijving van de methodiek
De probleemstelling en de vraagstelling moeten ongewijzigd worden overgenomen zoals ze werden gedefinieerd vóór dat het onderzoek begon. Het enige wat je nu kunt toevoegen is de methodiek. Het gaat hier over een bondige samenvatting waarin je vermeldt welke technologie je hebt gebruikt. Dus, net als bij een software architectuur, benoem je enkel de technieken zonder in technische details te vervallen.
Laten we een een voorbeeld nemen, in dit geval een wetenschappelijk artikel in Nature10 over het gebruik van een CNN om COVID-19 infectie in röntgenopnames te detecteren (Wang et al. 2020). Opgelet, het gaat hier om een wetenschappelijk artikel en dat is niet helemaal hetzelfde als een technisch rapport, maar in principe hebben beide ongeveer dezelfde opbouw.

Figuur 14.3: Overzicht van de onderdelen van de hoofding van Wang et al. 2020 zoals uitgebracht door Nature.

Figuur 14.4: Uitlichten van de structuur van een inleiding van Wang et al. 2020.
14.6 Methodiek
In een wetenschappelijk artikel spreekt men in het algemeen van Materialen en methoden (eng: Materials and methods). De bedoeling is om binnen dit onderdeel, dat ook binnen een rapport belangrijk is, een nauwkeurige beschrijving te geven van alle hardware en software componenten die gebruikt werden alsook de modus operandi van het onderzoek.
Een belangrijke doelstelling van Materialen en methoden is om ervoor te zorgen dat jouw analyses reproduceerbaar zijn. Dit houdt in dat elke andere datawetenschapper in staat moet zijn om, vertrekkende van de zelfde data, tot hetzelfde resultaat te komen.
Stelling 14.3 (Voorwaarden voor reproduceerbaarheid) Om het onderzoek reproduceerbaar te maken, moet er aan de volgende criteria voldaan worden:
- (tijdens onderzoek) Gebruik van een random seed (zie boven)
- Het moet duidelijk zijn welke hardware er gebruikt is tijdens de verschillende fasen van het onderzoek (pre-processing, trainen, testen, …)
- De data moet beschikbaar zijn of op zijn minst beschikbaar kunnen worden gemaakt
- Je geeft mee op welke subset van de data er gewerkt is
- Je geeft een volledig beeld van de data-flow, geschreven en/of met behulp van illustraties
Ben je niet zeker of je werk reproduceerbaar is? Kijk dan deze checklist na:
- Is de data beschikbaar?
- Staat jouw rapport onder versie-controle en heb je de link naar de repository gedeeld?
- Ben je geen software vergeten vermelden waar je onderzoek van afhangt? Een tekstverwerker of IDE zoals VSCode of andere standaard software zoals Microsoft Word moet je in principe niet vermelden (“Computer software & mobile applications - apa 6th referencing style guide - library guides at aut university,” n.d.), maar de versie van R, Python, TensorFlow, … bijvoorbeeld wél.
- Staan er in de code nog verwijzingen naar folders/API’s of andere hulpbronnen die zouden kunnen ‘breken’?
- Is er voor elke externe hulpbron een volledige beschrijving + referentie beschikbaar zodat de gebruikers deze kunnen opzoeken mocht er toch een link kunnen breken?
- Heeft de gemiddelde datawetenschapper voldoende aan jouw beschrijving om te begrijpen wat je hebt gedaan en ook waarom je het hebt gedaan?
- Kan elke data-element of variabele gevolgd worden van bron tot model?
Ben je nog steeds niet zeker? Test het dan gewoon uit. Geef het rapport (zonder tussen resultaat) met de data aan een persoon skilled in the art (nl: deskundige persoon) en vraag deze persoon om het geheel van scratch opnieuw uit te voeren. in de praktijk betekent dit dus typisch een archiefbestand met daarin de data en een rapport (*.Rmd-bestand) zonder enige tussen resultaten zoals bijvoorbeeld de resultaten van eerdere trainingen.
14.6.1 Data beschikbaar maken
Als je data verspreidt, probeer dan ervoor te zorgen dat je een formaat kiest dat robuust is en door iedereen geopend kan wordt ongeacht de achtergrond van de datawetenschapper en ongeacht het besturingssysteem. Bijvoorbeeld, gebruik een *.tsv-bestand (tab-separated values). Dit is vele male handiger dan de spijtig genoeg meer populaire *.csv-bestanden (comma-separated values) omdat hierbij met escapes gewerkt dient te worden indien de data zelf een komma bevat (escapes voor de komma is de dubbele quote, die op zijn beurt ook ge-escaped moet kunnen worden). Komma’s komen namelijk standaard voor in allerhande teksten zoals adressen, tweets, … terwijl het tabulatie-teken dit probleem niet heeft.
14.6.2 Beschikbaar maken van databanken
Gaat het om een volledige databank, dan kan uiteraard best de link meegegeven worden of een dump-bestand worden aangemaakt (bijvoorbeeld SQL *.bak-bestand). Zorg altijd dat het duidelijk is voor de ontvanger hoe er connectie met de databank gemaakt kan worden en om welk type databank het gaat (Oracle, MySQL, MSSQL, PostgreSQL, MongoDB, SAS, …) en vermeld de versie waar relevant. Probeer ervoor te zorgen dat de oorspronkelijke en/of huidige auteurs van de databank een eervolle vermelding krijgen. Probeer ook ervoor te zorgen dat de betekenis van elke variabele duidelijk is. Geef de gebruiker de kans om zelf data te kunnen exploreren.
14.6.3 Procesbeschrijving
Naast het aspect van reproduceerbaarheid moet de beschrijving van de methodiek er ook voor zorgen dat er bij het doelpubliek een goed begrip ontstaat van de motivatie bij de verscheidene stappen binnen de analyse. Met andere woorden, probeer duidelijk te maken waarom je hebt gedaan wat je hebt gedaan. Eén aspect hiervan is het duidelijk maken waar elke variabele voor gediend heeft in een soort data-flow. Dat kan héél eenvoudig zijn voor kleine projecten, maar kan in grotere projecten veel complexer worden en eventueel als addendum toegevoegd aan het verslag. Hoe complex een DFD moet zijn hangt af van wie er wat mee moet doen.
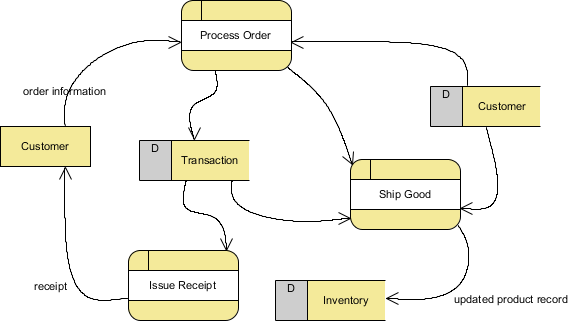
Figuur 14.5: DFD diagram zoals gedemonstreerd door Visual Paradigm (bron).

Figuur 14.6: Voorbeeld van een DFD binnen de wereld van BI.
14.6.4 Voorbeeld uit Wang et al.
Zoals we in ons voorbeeld kunnen zien vormt de omschrijving van de data en handelingen een belangrijk onderdeel van een wetenschappelijke publicatie. Voor een verslag moet je niet zo in de diepte gaan als bij een technische documentatie en alles hangt natuurlijk sterk af van het publiek.
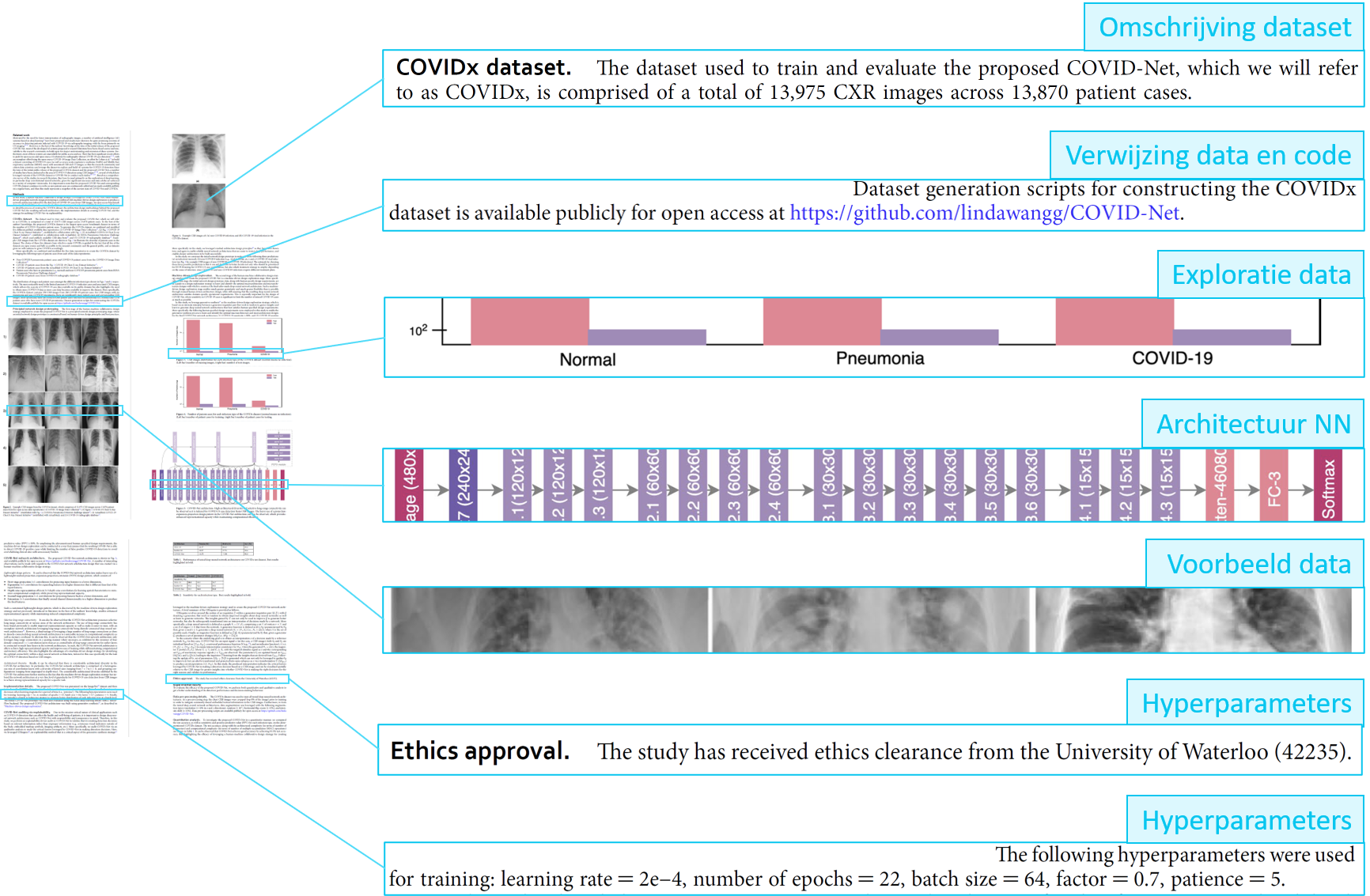
Figuur 14.7: Overzicht van de onderdelen van de methode beschrijving van Wang et al. 2020.
14.7 Resultaten
Resultaten zijn het zwaarst om te verzamelen maar het meest eenvoudige om neer te schrijven. Het is namelijk een, weliswaar gestructureerde, opsomming van feitenmateriaal.
14.7.1 Beduidende cijfers

Figuur 14.8: Hoe hoog is de Eiffeltoren? bron
Tijdens het onderzoek kom je allerhande getallen tegen en het is toch niet slecht om even te blijven stilstaan bij de cijfers (eng: digits) die deze getallen (eng: numbers) opmaken. Significante of beduidende cijfers (eng. significant figures) zijn die cijfers van een getal die informatie overdragen. bijvoorbeeld, bij het getal 12.345 veronderstel je (zonder verdere context) dat het 5 beduidende cijfers heeft.
Vertelt iemand je dat de Eiffeltoren 324.00248975 m hoog is, dan weet je natuurlijk dat niet elk cijfer hiervan significant kan zijn, alleen al omdat door de thermale expansie de hoogte van de Eiffeltoren in de winter en de zomer meer dan 10 centimeter kan verschillen.
De Eiffeltoren is dus 324 m hoog, zonder meer. Het exacte aantal beduidende cijfers kan je statistisch bepalen als je een over een toepasselijke steekproef van de meting beschikt en de tussenstappen van de berekeningen kent (cfr. foutenpropagatie). Het is een kwestie om het onderscheidend vermogen in te schatten van de grootheid in kwestie en daar rekening mee te houden.
round(56.25, 1) = 56.2, niet 56.3! Lees hier meer over door ?round in te geven.
14.7.2 Onzekere cijfers
Denk eraan dat, tenzij je uitspraken doet over natuurkundige constanten, aantallen of rangvolgorden, er bij elke cijfer in principe een onzekerheid past. Dit geldt voor zowel de ruwe data als de berekende gegevens. Laten we een aantal voorbeelden beschouwen:
discoveries dataset geeft het aantal grote ontdekkingen weer tussen 1860 en 1959 (McNeil and Conway 1977). Het gaat hier wel degelijk om natuurlijke getallen waar geen fout op bestaat. Het gaat dus om discrete numerieke waarden met een stapgrootte van 1.
## Time Series:
## Start = 1860
## End = 1959
## Frequency = 1
## [1] 5 3 0 2 0 3 2 3 6 1 2 1 2 1 3 3 3 5 2 4 4 0 2 3 7
## [26] 12 3 10 9 2 3 7 7 2 3 3 6 2 4 3 5 2 2 4 0 4 2 5 2 3
## [51] 3 6 5 8 3 6 6 0 5 2 2 2 6 3 4 4 2 2 4 7 5 3 3 0 2
## [76] 2 2 1 3 4 2 2 1 1 1 2 1 4 4 3 2 1 4 1 1 1 0 0 2 0Het zou inderdaad vreemd zijn om te zeggen dat er in 1885 12.2814 i.p.v. 12 grote ontdekkingen waren. Dus op het getal 12 staat geen fout. De bron staat in R altijd bij de hulp-pagina maar is nogal oud (McNeil and Conway 1977) en moeilijk terug te vinden. Maar het leidt uiteindelijk naar de echte bron: The world almanac and book of facts, 1975-, 1975. Het enige wat we weten is dat het om tellingen van ‘grote’ ontdekkingen zijn, zonder uitleg over mogelijke criteria die gehanteerd werden over wat precies een grote ontdekking is. Dus die aantallen zijn zeker ‘niet zeker’, maar het is bijna onmogelijk om te achterhalen hoe onzeker de gegevens precies zijn.

Ontdekkingen uit de 1975 editie van “The World Almanac and Book of Facts”
## Girth Height Volume
## 1 8.3 70 10.3
## 2 8.6 65 10.3
## 3 8.8 63 10.2
## 4 10.5 72 16.4
## 5 10.7 81 18.8
## 6 10.8 83 19.7
## 7 11.0 66 15.6
## 8 11.0 75 18.2
## 9 11.1 80 22.6
## 10 11.2 75 19.9Wel, we kennen de onzekerheid op basis van de beduidende cijfers, maar we weten niet of de oorspronkelijke auteur wel het juist aantal beduidende cijfers heeft gebruikt. We zouden de bron, namelijk Atkinson 1987, kunnen uitpluizen en nagaan met welk instrument de metingen werden uitgevoerd en wat de kleinste eenheid is op dat meetinstrument. Dan weet je nog niet hoe gemakkelijk het is om de diameter van een vogelkers te meten op ongeveer 1.4 meter hoogte en hoeveel afwijking op de meting te wijten is aan de nauwkeurigheid van de wetenschapper.
Wat je wel kan doen is op basis van gemiddelden en standaardafwijkingen de spreiding op de meetresultaten na te gaan. Laten we bijvoorbeeld het volume van de bomen onder de loep nemen:
trees$Volume %>% density %>% mirror(c(0, Inf)) %>%
plot(main = "Volumes of Black Cherries", xlab = "Volume")
volume_mean <- trees$Volume %>% mean
volume_stdv <- trees$Volume %>% sd
abline(v = volume_mean, lty = 2)
polygon(
rep(c(-1, 1) * volume_stdv + volume_mean, each = 2),
c(-1, 1, 1, -1), col = "#50DBF955", border = NA)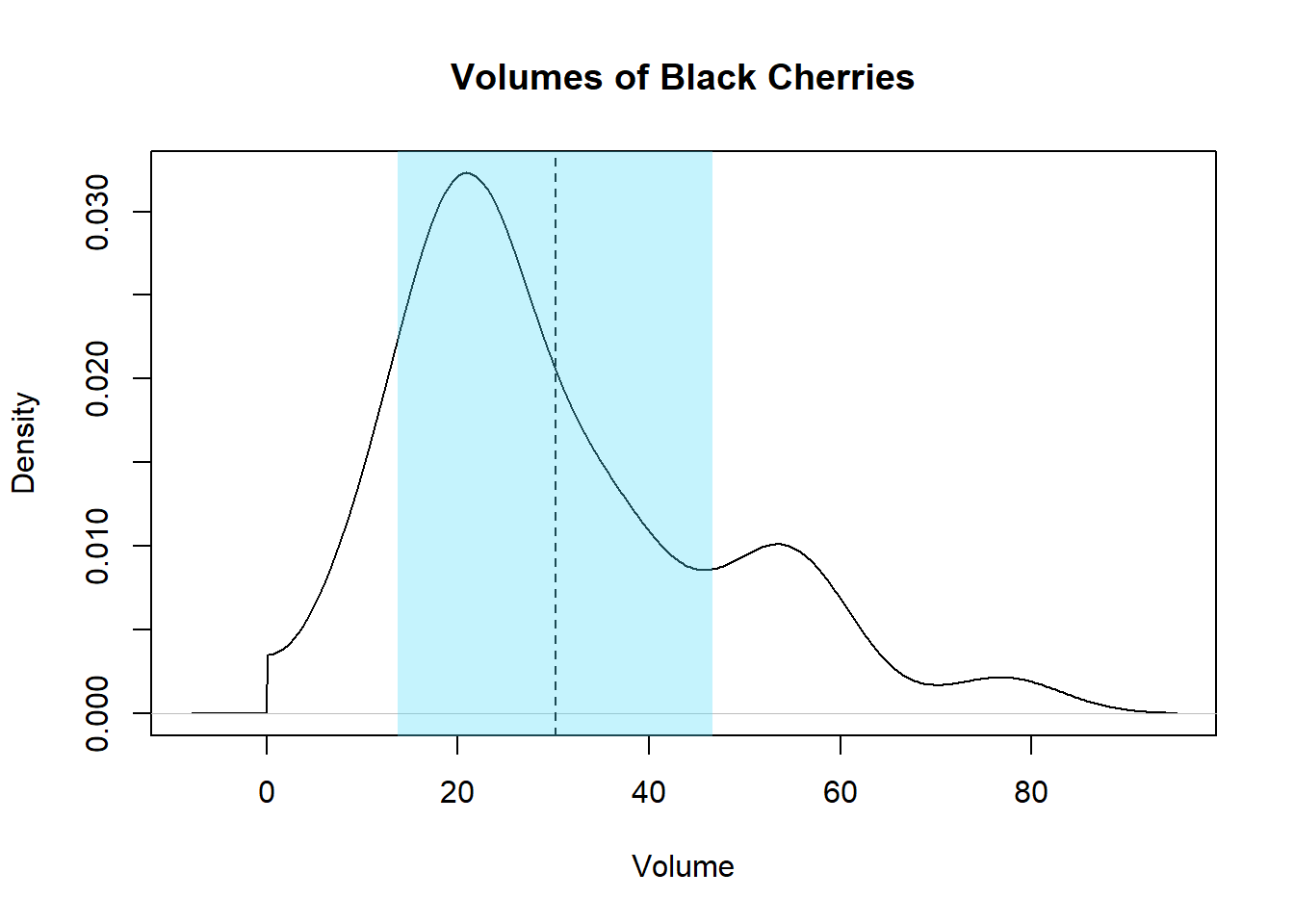
Het gemiddelde volume kan gerapporteerd worden als:
30.17 ± 16.44
, maar als je nu even terug naar de verdeling kijkt voel je natuurlijk aan, zoals eerder reeds aangehaald, dat dit getal geen voldoende voorstelling van de spreiding meegeeft.
14.7.3 Visuele cijfers
Eén beeld is als 1000 woorden, zo gaat het gezegde. Probeer daarom ook altijd goed na te denken in welke vorm je bepaalde gegevens wil voorstellen. Denk goed na over zowel de vorm als de inhoud. Maak de visualisatie niet complexer dan noodzakelijk (Figuur 14.9D). Denk ook aan je publiek. Indien het om een geïnformeerd publiek gaat, mag je gerust wat elementen toevoegen aan de grafiek (Figuur 14.9E) zodat je niet telkens tussen tabel en grafiek moet omschakelen. Denk er ook aan dat in sommige visualisaties de volgorde van de elementen een belangrijke rol spelen. Bij een bevolkingspiramide als in Figuur 14.9A is de volgorde impliciet aan de gegevens, maar soms moet de volgorde opgelegd worden om de interessante patronen te ontdekken. Zo is de volgorde van de patiënten in Figuur 14.9B noodzakelijk om het patroon in de behandelingsperiodes tot uiting te laten komen.
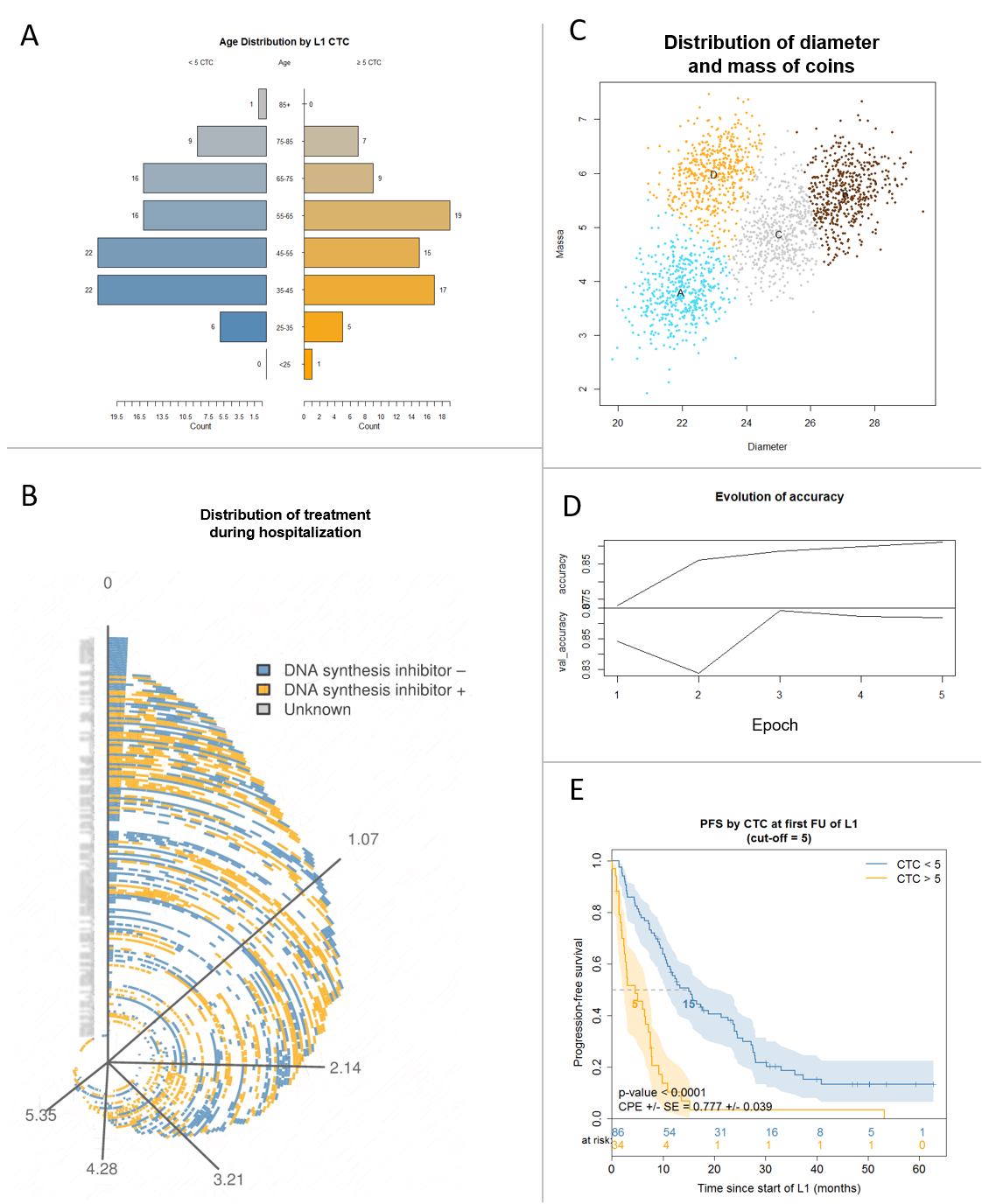
Figuur 14.9: Voorbeeld visualisaties. A. Distributie van leeftijd bij twee cohorten. B. Verdeling van de behandelingsperiode met een DNA synthese inhibitor gedurende de hospitalisatie van een honderdtal patiënten wiens identificatienummers vertroebeld werden om privacy redenen. C. Figuur uit § Leren versus ontwerp. D. Figuur uit § Sentiment analyse. E. Figuur uit technisch rapport omtrent de efficiëntie van een diagnosetechniek om progressie in borstkanker op te sporen.
Resultaten visualiseren doe je niet enkel met figuren. Ook tabellen zijn een vorm van visualisatie en de complexiteit ervan, en dus ook de tijd die nodig is om een bevredigend resultaat te bekomen, wordt vaak onderschat (Figuur 14.10).

Figuur 14.10: Overzicht van de onderdelen van de resultaten uit Wang et al. 2020.
14.8 Discussie en Conclusie
Het is in de conclusie dat de onderzoeker de resultaten voor het eerst interpreteert. Indien dit onderdeel voldoende groot is wordt het dan ook opgesplitst in twee onderdelen: de discussie met de interpretatie en de eigenlijke conclusie met enkel een bondige herhaling van het ganse artikel. Hier wordt de term conclusie gebruikt om de discussie te bevatten.
In de conclusie geeft de auteur mee wat die in de resultaten ziet. Het is dan aan de lezer om te bepalen of die hetzelfde ziet in de resultaten. Vandaar het belang om resultaten en conclusie altijd volledig gescheiden te houden. Resultaten, indien op een correcte manier verzameld, staan los van de vooringenomenheid van de onderzoeker. In werkelijkheid is inderdaad iedere onderzoeker in meer of mindere mate vooringenomen, bewust of onbewust. Het is hier, in de conclusie dat de auteur dus eindelijk diens eigen mening mag uiten.

Figuur 14.11: Dissectie van de conclusie van Wang et al. 2020.
De conclusie is vermoedelijk het allermoeilijkste onderdeel van het verslag. Het is het stuk waarover vaak het meest gedebatteerd wordt en waarin je kennis over de materie moet tentoon spreiden. Het is vaak ook het onderdeel waar een lezer als eerste naartoe gaat om meteen de conclusie te horen zonder doorheen het volledig verslag te moeten bladeren. Het moet dus goed zijn! Maar wat zijn de regels daarrond? Wanneer is een conclusie goed genoeg?
Uiteraard is elke conclusie anders en sterk afhankelijk van het onderwerp en de resultaten. Dus onderstaande regels moet je niet altijd even strikt nemen en gelden als een algemene gids:
- Indien van toepassing (zie hierboven) geef je een zeer bondig overzicht van de uitgevoerde acties
- Vermijd eindeloze herhaling van de resultaten, vermijd hier zoveel mogelijk het gebruik van getallen
- Plaats jouw werk in perspectief t.o.v. gelijkaardig werk door anderen (afhankelijk van de situatie kan je dit ook wel eens in de resultaten terug vinden)
- Vermijd elke vorm van opschepperij
- Blijf kritisch over jouw resultaten, bedenk dat je nooit 100% zeker bent van de (positieve) resultaten
- Verkondig een mening, hier moet je zeker veel verder gaan dan het beschrijven van de resultaten
- Blijf politiek correct en respectvol tegenover anderen
- Beschrijf wat volgens jou (en andere mogelijk co-auteurs) de impact is van jouw (jullie) bevindingen
- Geef je mening omtrent wat er nog beter zou kunnen aan het onderzoek
- Openbaar wat de toekomstplannen zijn op dit onderwerp
In de discussie en conclusie is het dus de bedoeling dat de auteur diens werk vergelijkt met dat van andere, onafhankelijke onderzoekers. De bedoeling is om hier een soort landschapsanalyse te doen, m.a.w. na te gaan in hoeverre jouw resultaten overeenkomen met die van andere. Uiteraard heeft niemand exact hetzelfde onderzoek gevoerd zoals jij dat hebt gedaan, maar toch is het belangrijk om uit te zoeken wie ‘iets gelijkaardig’ heeft gedaan en wat daar de resultaten van waren. Natuurlijk is het dus ook belangrijk om correct naar andermans werk te kunnen verwijzen en daar gaat de laatste paragraaf over.
14.9 Afsluiten met de samenvatting
Vaak wordt er verwacht dat er een samenvatting vooraan in de tekst wordt meegegeven.
Dat betekent dat van inleiding tot en mét de conclusie samengevat dient te worden. het kan dan ook niet anders dan dat je de samenvatting helemaal op het einde schrijft.
14.10 Verwijzen naar extern werk
14.10.1 Citeren
De stijl van citeren hangt af van de organisatie waarin je je bevind. Voor het departement WT binnen AP is er bijvoorbeeld de Schrijfwijzer. Daarin staat dat AP de APA stijl aanhoudt.
14.10.2 Licenties en toestemming
Het plagiëren is niet beperkt tot menselijke talen. Het gaat immers over ideeën! Bij het ontlenen van scripts of code, in eender welke programmeertaal is het belangrijk om dezelfde regels aan te houden als voor menselijke talen. Dat betekent, bij elke stukje ontleende code moet een verwijzing naar de bron of citaat toegevoegd worden! Maar er is meer! Het is namelijk zo dat er aan code licenties vasthangen. Op choosealicense krijg je een overzicht van de meest voorkomende licenties die gebruikt worden op GitHub.
Bronvermelding
Atkinson, A.C., 1987. Plots, transformations, and regression: An introduction to graphical methods of diagnostic regression analysis, Oxford science publications. Clarendon Press.
Computer software & mobile applications - apa 6th referencing style guide - library guides at aut university, n.d. (Accessed on 12/09/2020).
McNeil, D.R., Conway, D., 1977. Interactive data analysis: A practical primer. Wiley.
Mélard, G., 2014. On the accuracy of statistical procedures in microsoft excel 2010. Computational statistics 29, 1095–1128.
Pottel, H., 2003. Statistical flaws in excel. Innogenetics NV, Technologiepark 6, 9052.
The world almanac and book of facts, 1975-, 1975.. World Almanac Books.
Wang, L., Lin, Z.Q., Wong, A., 2020. Covid-net: A tailored deep convolutional neural network design for detection of covid-19 cases from chest x-ray images. Scientific Reports 10, 1–12.